ChatWithRTX:添加Baichuan2支持中文检索!
由于自带的两个模型Mistral和Llama,对中文的支持不太理想,所以准备换成比较好的国产开源模型Baichuan2 。
替换成功之后,就可以进行中文提问,中文检索,中文回答了。
即便是有大量的英文文档,也可以用中文提问,然后中文回答。
这个就相当吊了!
先给大家看一下设置好之后的样子。
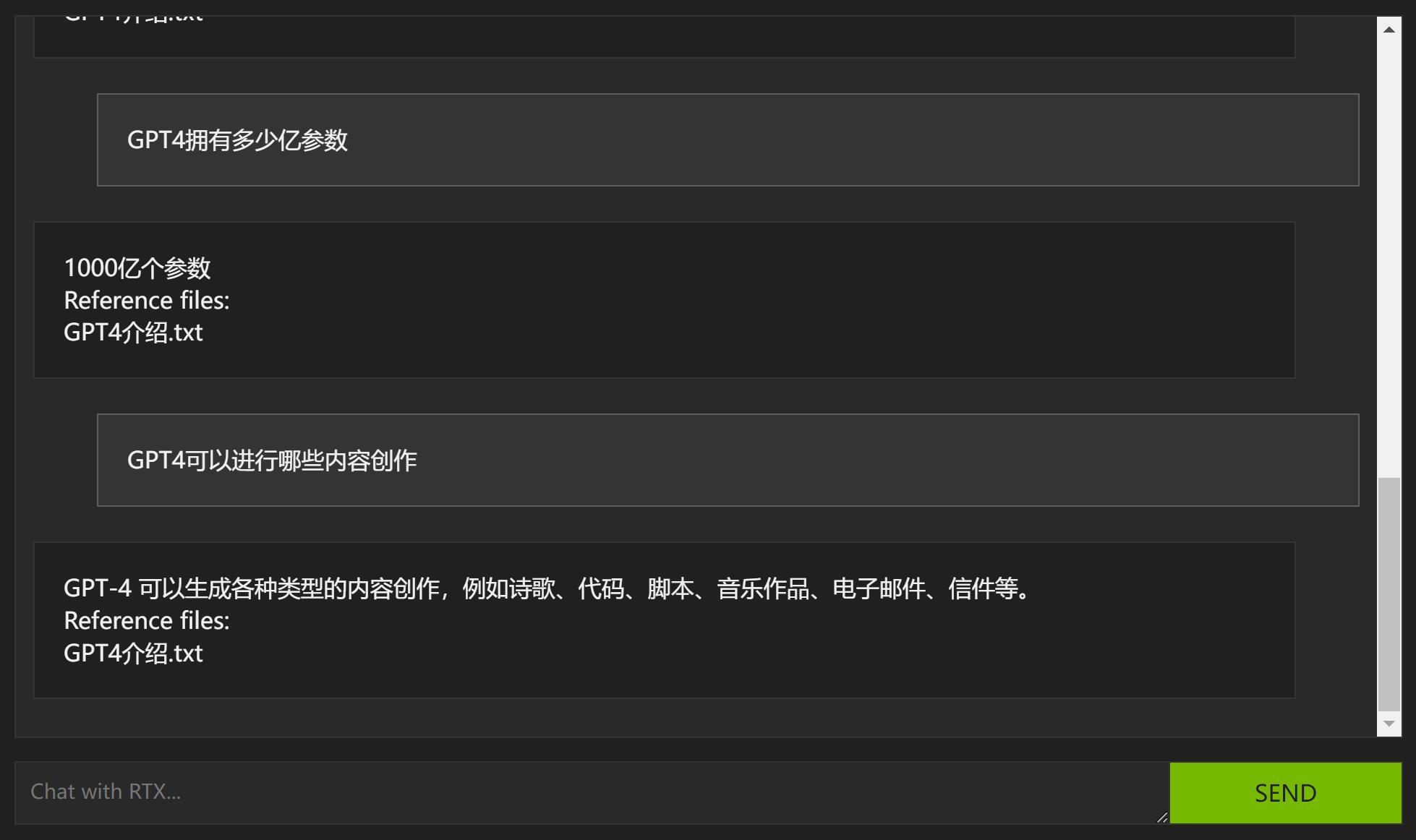
只要输入中文提问,AI就能帮你找到答案和出处。
文档出处和内容定位相当精准!
为了实现这样的效果。
我们需要先获取中文模型,然后对中文模型进行一定的处理,然后修改配置文件,最后就可以使用了。
下面就来说说具体的操作过程。
1.获取中文模型
这次用到的中文模型是百川2(Baichuan2),用在中文检索上效果挺不错。
获取模型并不难,方法有很多。
下面就说三种获取方式。
①代码下载
from modelscope import snapshot_download
model_dir = snapshot_download('baichuan-inc/Baichuan2-7B-Chat')
②git命令下载
git clone https://www.modelscope.cn/baichuan-inc/Baichuan2-7B-Chat.git③ 直接去我网盘获取!
懂的用上面的命令,不懂的直接网盘!
2.模型构建
这一步的核心目的,就是把原始的模型做一个转换,变成ChatWithRTX能识别和使用的格式。说起来其实还是比较简单,但是真搞起来还是有一定的难度。
ChatWithRTX这个项目是基于trt-llm-rag-windows ,而这个项目又是使用了TensorRT-LLM来对模型进行加载和加速。
也就是要替换模型,就必须要安装配置TensorRT-LLM这个项目。而这个项目的配置显然不是入门级的,涉及到相对比较多,比较复杂的设置。
看着配置说明就有点望而生畏,所以我准备投机取巧一下!
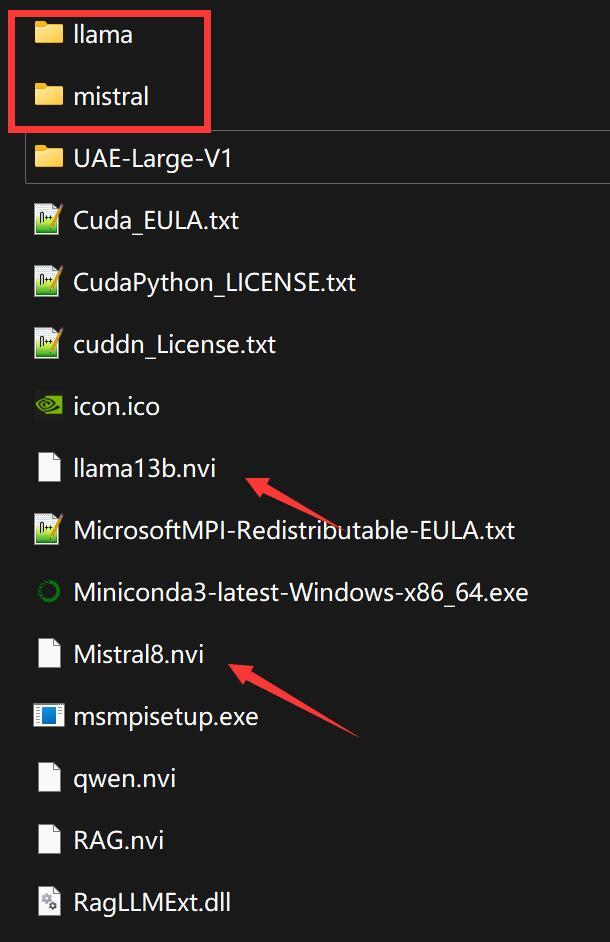
经过我简单的研究发现,CWR这个软件在安装过程,会去读取.nvi文件来进行模型的编译和安装。也就是说,一个模型配合一个nvi配置文件。
打开nvi文件,对比软件自带的Mistral和Llama可以发现,不同的文集只是改了一个模型名称而已。
所以我认为只要下载baichuan模型,然后自己编写一个nvi文件。然后从新装一遍,中文模型就有了。
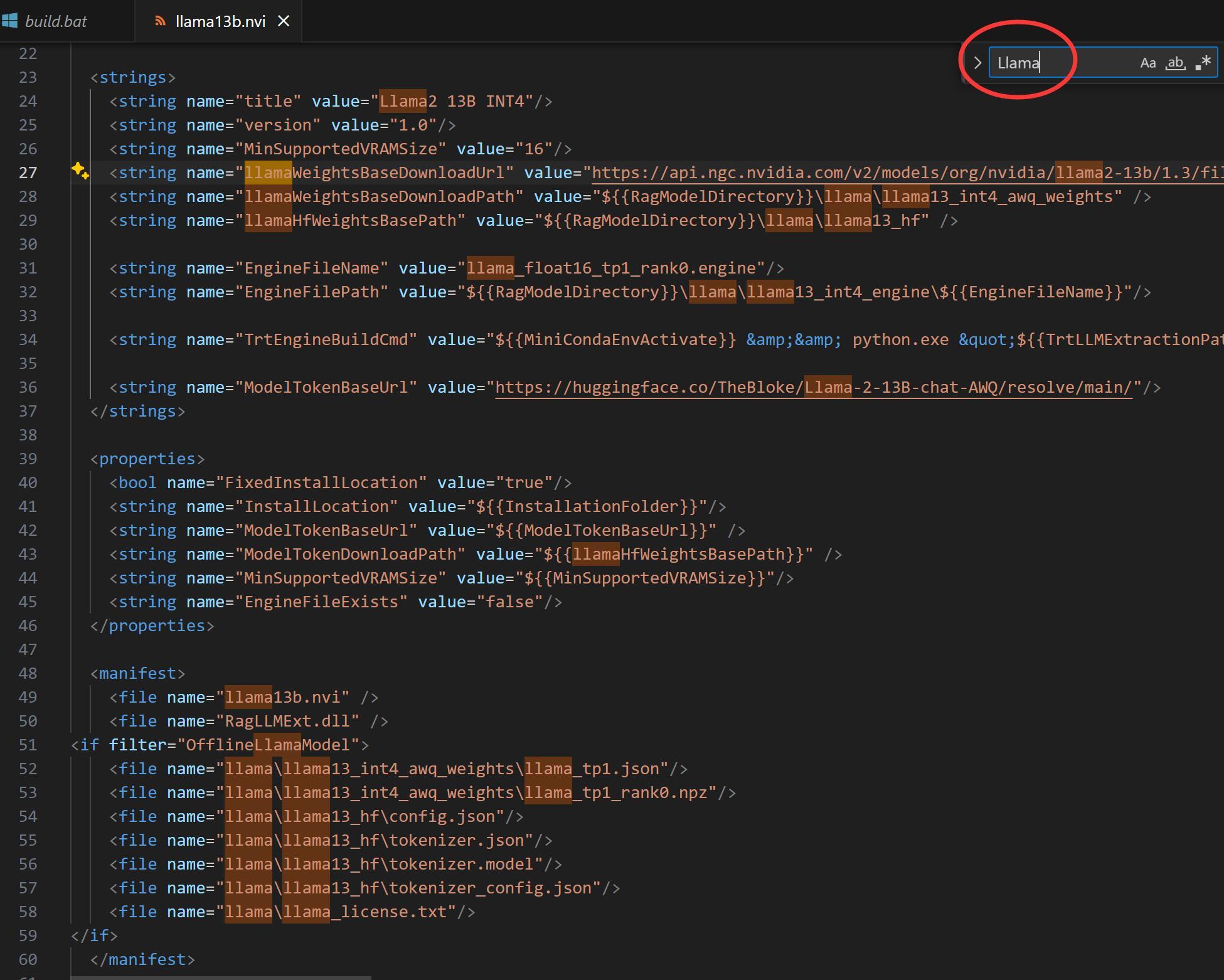
当我正在为这个发现沾沾自喜的时候,一个致命打击出现了。
CWR自带的两个模型并不是常规的模型格式,而是一种以npz文件,我不是很清楚他是用什么方式做了转换。
这么一来,这种方案只能放弃了。
那么只能老老实实去装TensorRT-LLM来对模型进行构建了?
查阅了一些文章和视频后,还是发现了一个捷径。
CWR在安装的时候,其实已经帮你配置好了一个可以运行TensorRT-LLM的Python环境了。虽然那个版本比较老了,但是完全可用!
所以,我们可以使用自带环境来快速构建目标模型。
具体的CMD命令如下:
cd I:\Run\NVIDIA_ChatWithRTX21\TensorRT-LLM\TensorRT-LLM-0.7.0\examples\baichuan I:\Run\NVIDIA_ChatWithRTX21\env_nvd_rag\python.exe build.py --model_version v2_7b --model_dir I:\Baichuan2\Baichuan2-7B-Chat --dtype float16 --use_gemm_plugin float16 --use_gpt_attention_plugin float16 --use_weight_only --weight_only_precision int4 --output_dir I:\Baichuan2\trt_engines\Baichuan2\1-gpu --max_input_len 3072
命令这个东西密密麻麻,乍看还是挺吓人!
我稍微做个解释。
第一行cd命令是的含义是,切换命令执行的目录,切换到我们安装好的CWR下面的TensorRT-LLM项目的相关目录中。
比如要构建baichuan的模型就进入examples\baichuan的文件下面。
然后使用CWR安装时配置好的Python环境运行Build.py,当然后面还要跟一堆参数。
参数挺多,但是我们只要关注三个即可。
–model_version 是指定模型版本,这里用到了baichuan2中的7B版本。
–model_dir 指的是原始模型的存放路径,这个原始模型,就是上面下载的模型。
–output_dir 这个是构建完成后,新生成的模型的保存路径。
详细的编译参数,可以参考项目自带的Readme文件。
运行后的截图如下:
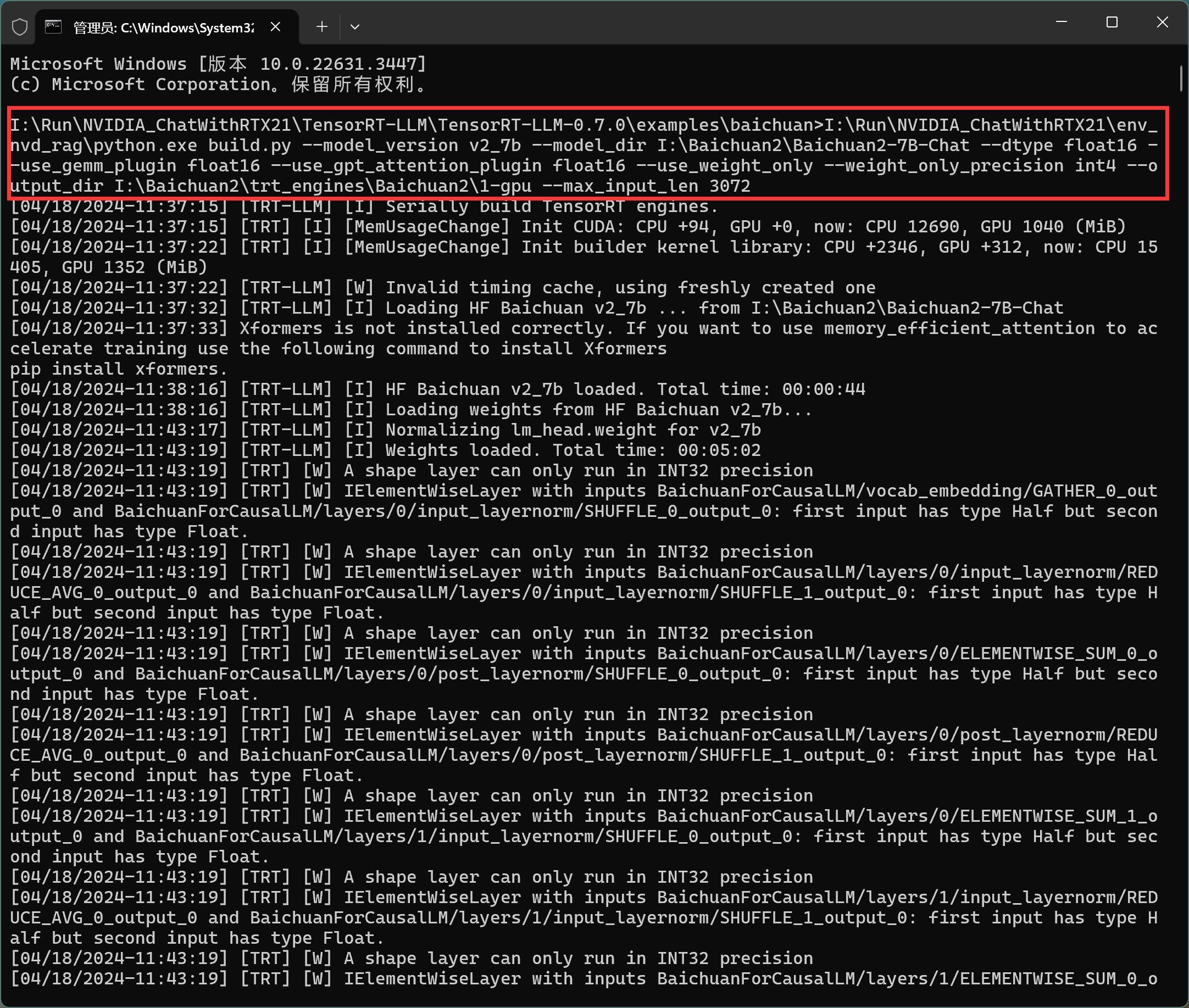
运行过程,内存,CPU,磁盘,GPU使用率都比较高。
如果硬件配置比较低,我不确定会发生什么事情!
运行过程中会出现一些警告(warming),一般不用管它。
我的电脑大概用了10分钟左右,就构建完成了!
构建完成后,会在我们指定的目录下生成如下文件:
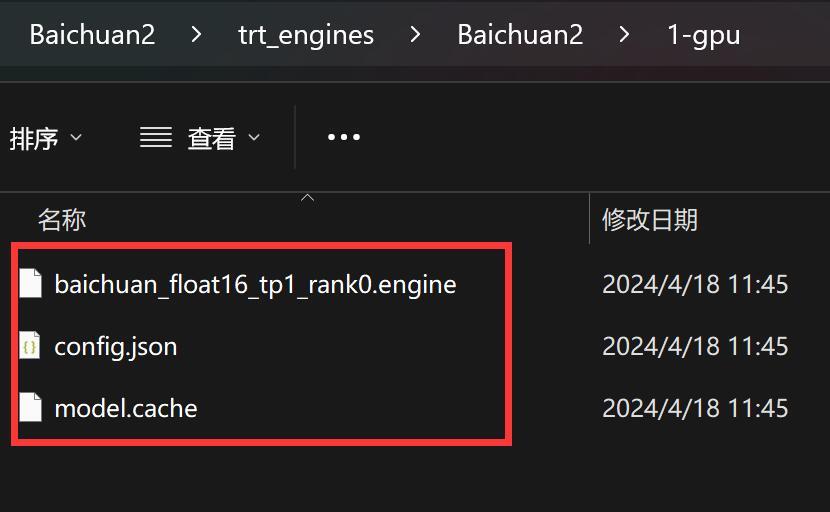
这些文件就是我们需要的模型文件。
3.放置模型
模型构建完成之后,就需要把这些文件拷贝到CWR的model目录下面。
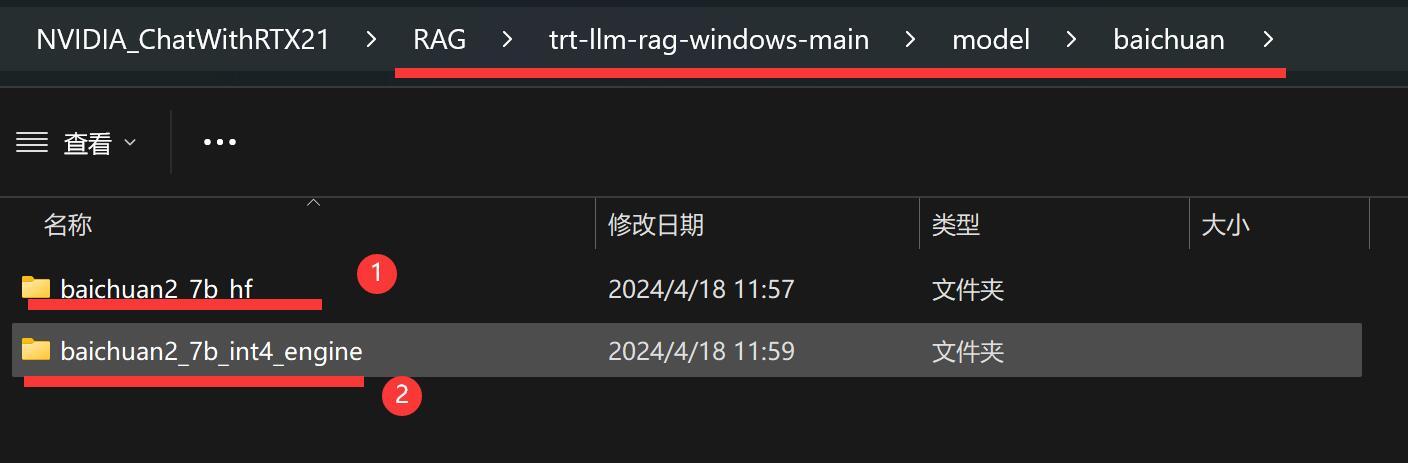
在model目录下面创建一个叫baichuan的文件,文件夹里放两个子文件夹。
一个是baichuan2_7b_hf,这里放我们下载到的原始模型,其实只用了原始模型的token相关文件。为了减小难度,你就把整个模型文件夹里的文件都拷贝到这里吧。
一个是baichuan2_7b_int4_engine,这里就放我们上面构建生成的三个文件。
就是一个放老的,一个放新的,这样应该好理解。
到这一步,我们离成功就不远了。
4.修改配置文件
模型放置到位之后,还需要修改一下配置文件。
配置文件路径:
RAG\trt-llm-rag-windows-main\config\config.jsonRAG就是CWR安装目录下的一个文件夹。
用任意文本编辑器打开这个文件。
找到这个文件之后,添加一些内容。
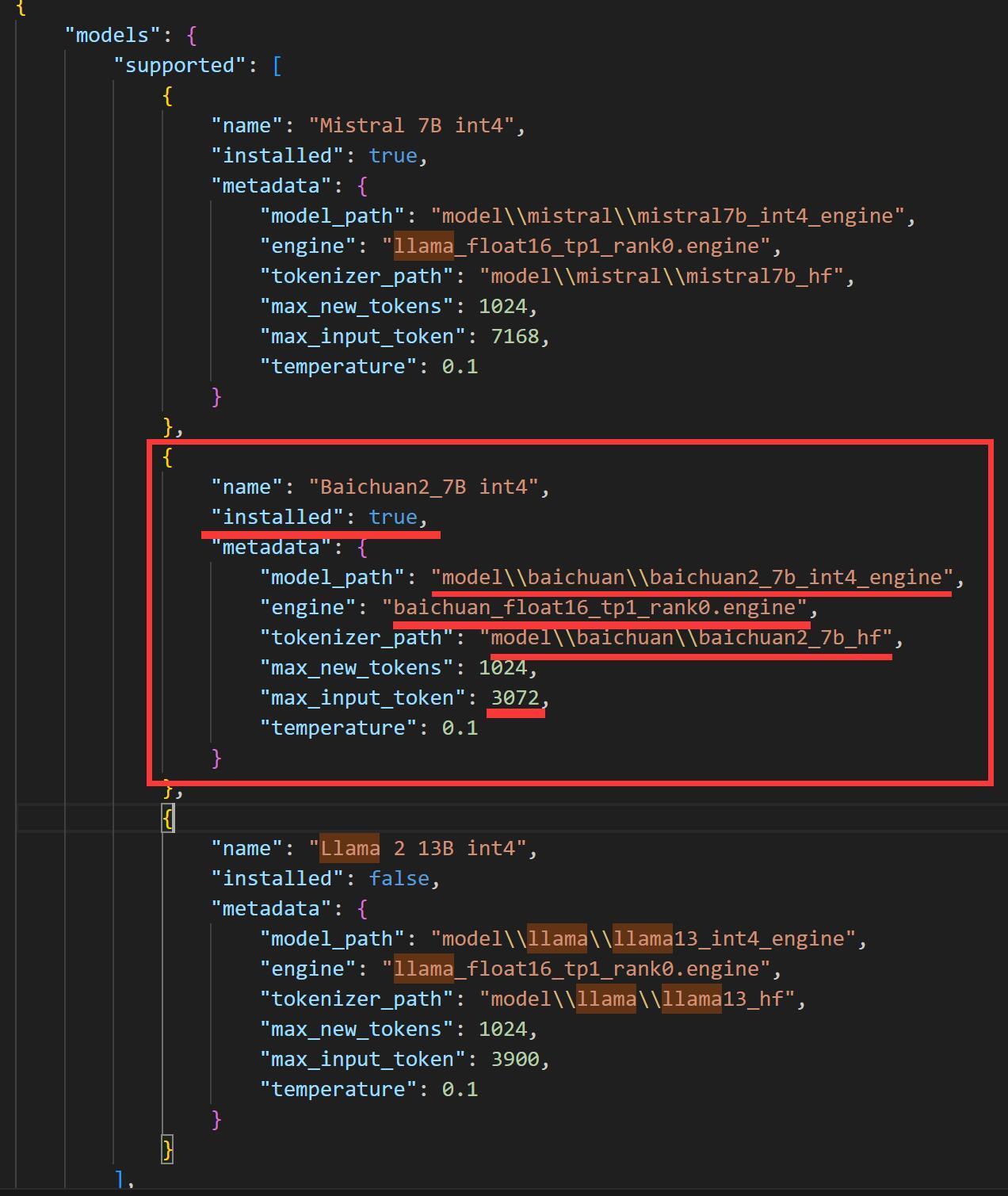
具体的的添加方式,就是拷贝一条Mistral的内容,把{}和它里面内容全部拷贝一份。注意大括号前后都要加逗号。
然后修改下面几个项目:
名字(name)
是否安装(installed)
模型路径(modelpath)
引擎(engine)
分词器路径(tokenizer_path)
最大输入 token ( max_input_token)
因为这里用的是相对路径,所以可以完全照抄我的截图!
注意别打错字母,符号,空格!!!
5.运行软件
修改完配置文件,就可以使用CWR的快捷方式启动软件了。
软件启动之后,在模型选择的地方(Select AI model)就能找到Baichuan2的模型了。
选中这个模型,就可以使用了。
CWR默认带的一个文件集合为全英文内容。现在我们有了中文模型,所以我们应该搞些中文文档来进行测试。
我是创建了一个名为mydataset的文件夹,里面放了三个记事本文件。
分别是:
- Gemini介绍
- Grok介绍
- GPT4介绍
这些文件里具体的内容,都是让GPT4生成,未必准确,主要是为了验证检索效果。
比如Grok介绍.txt里的内容如下:
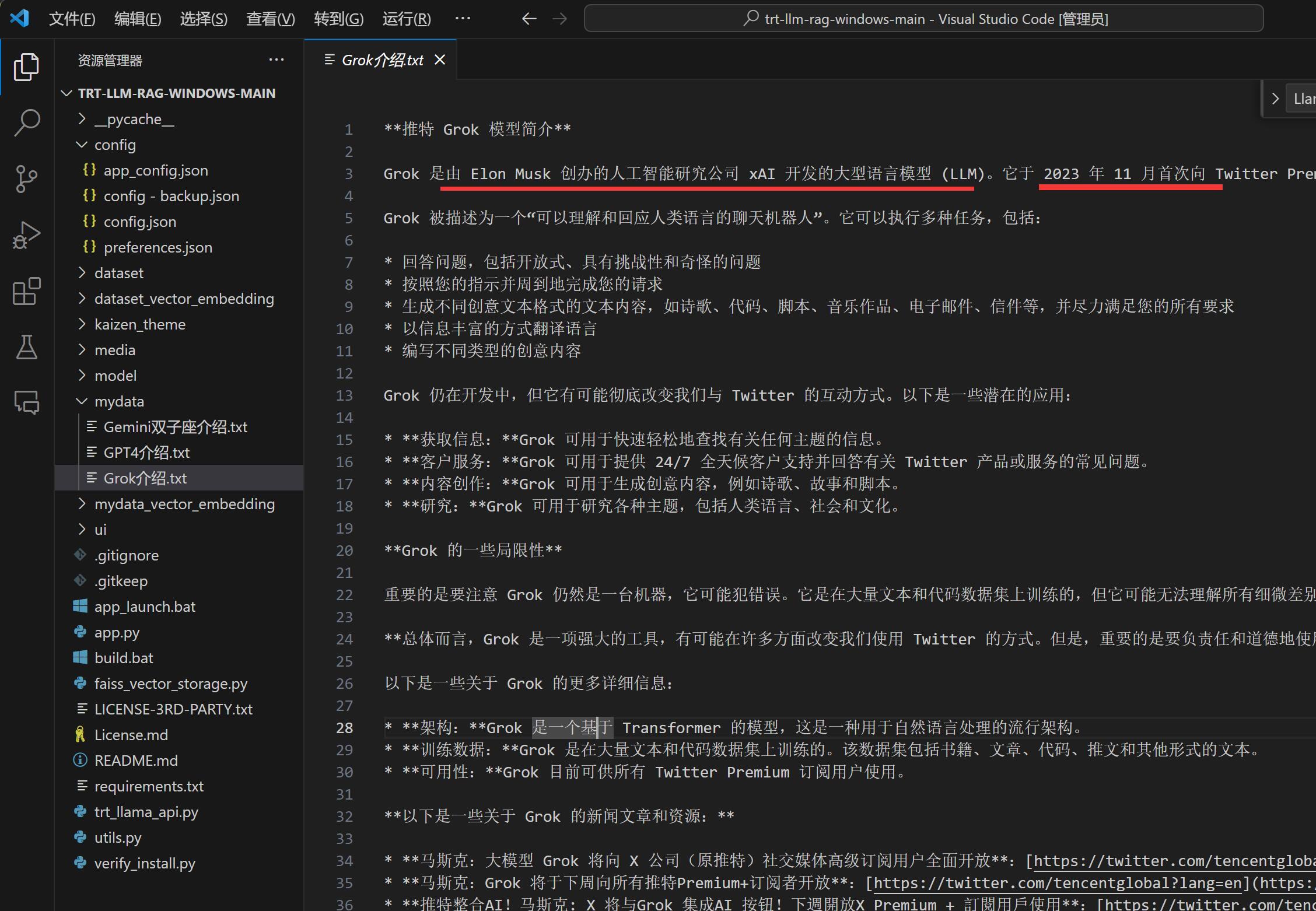
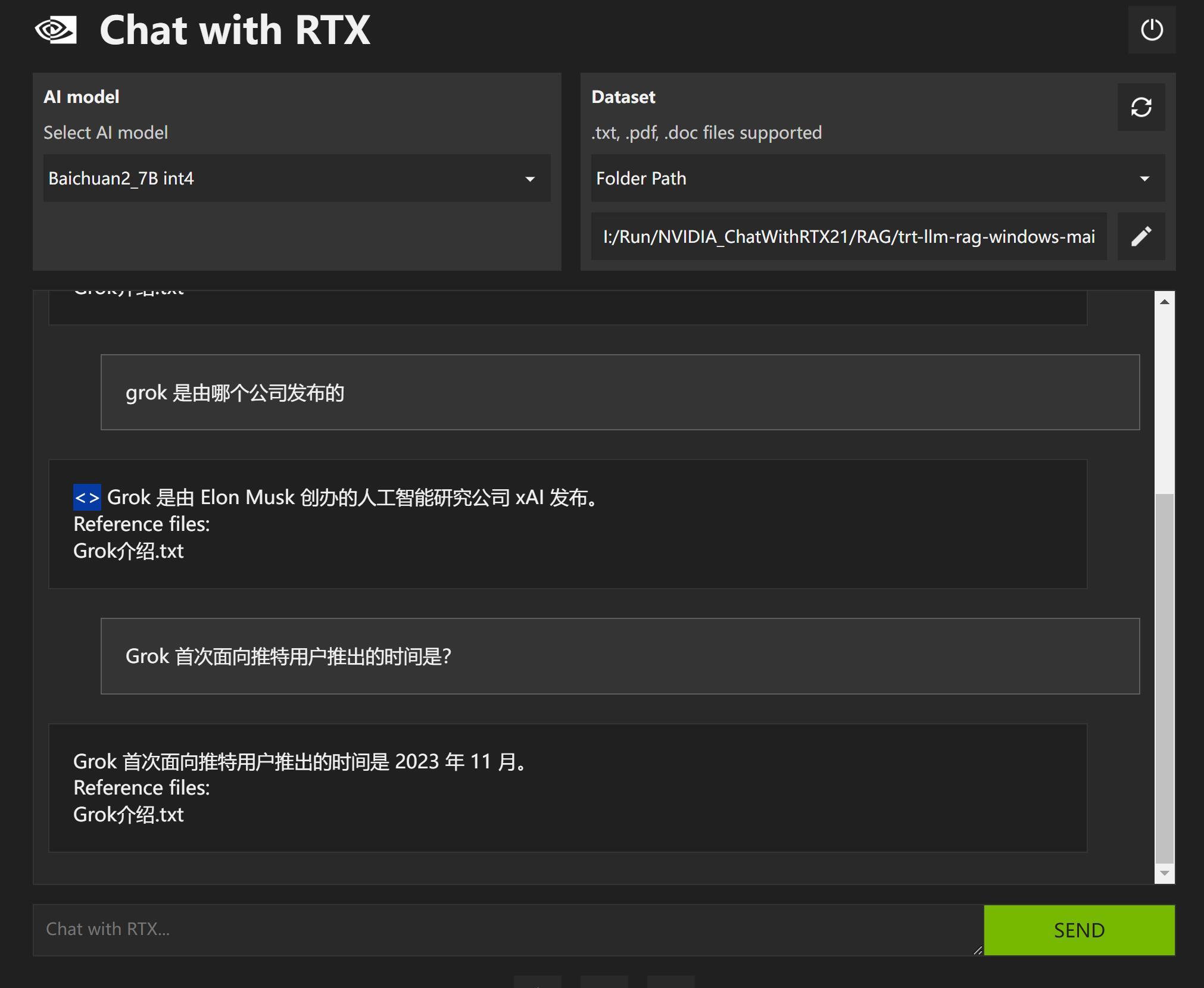
从上面的截图中可以看到,当我们提问明确的时候,找到的内容也非常精准。
而且它是完全按我们的提问来呈现内容,并没有长篇大论,把整个段落扔给我们。
当我提问:“Grok是由哪个公司开发的?”
它回答:“Elon Musk 创办的人工智能研究公司 xAI发布。”
当我提问:“Grok 首次面向推特用户推出的时间是?”
它回答:“Grok 首次面向推特用户推出的时间是2023 年 11 月。”
因为网上已经有大量的参考资料,这次切换模型,整体来说还是比较成功。
但是,在这个环境下,这个构建好的模型,用来直接对话的话,总感觉傻傻的,有点问题。
我不确定是啥问题!
今天就这样了,收工。
如果你们还没有ChatWithRTX安装包和相关模型,
可以给公众号“托尼不是塔克”发送消息“cwr” ,直接从网盘获取!
关于作者
tony
I am nobody !