使用ollama,MacOS也能轻松玩转大语言模型
我很少讲如何在苹果电脑上运行AI软件,因为M系列的GPU用起来确实有点难受。
但是如果你仅仅是想运行大语言模型,目前其实已经有比较好的方案了。
只要安装一个软件,一行命令,就能在本地流畅运行LLM。
操作非常简单,对话也很流畅。
今天要用到软件叫Ollama。
软件图标是一个只可爱的羊驼,从这个造型就知道它肯定支持Llama。
软件介绍很简单,就是说在本地启动并运行大语言模型。
支持的模型有Llama2,Code Llama 和其他模型,可以自定义创建自己的模型。
支持的系统有macos,Linux, Windows。
其实我们之前介绍过的lmstudio也挺不错,但是它只支持M系列苹果电脑。
无法在早期(<=2020年InterCPU)的苹果电脑上运行。
而我刚好搞了一台2019年顶配的Imac。
这个时候ollama就非常有用了。

略微吐槽下!
这配置,如果自己组装的话4K绝对能搞定了吧?
苹果一上手,就超20K了,现在买二手也得10k…
下面就用这台电脑做个演示,在上面跑跑谷歌Gemma和阿里Qwen。
另外,强调下lmstudio不光能运行大模型,也可以提供API服务哦。
1.下载软件
直接打开软件官网,点击Download ,开始下载。(网址见文末)
下载完成之后是一个zip为后缀的压缩包。
双击压缩包,就会自动解压。解压之后出现两个羊驼,一个是一代羊驼,一个是二代羊驼。(这个界面上,还是有一个重点提示,6W了啊…)
2.安装并运行软件
选新不选旧,直接双击Ollama2开始安装。
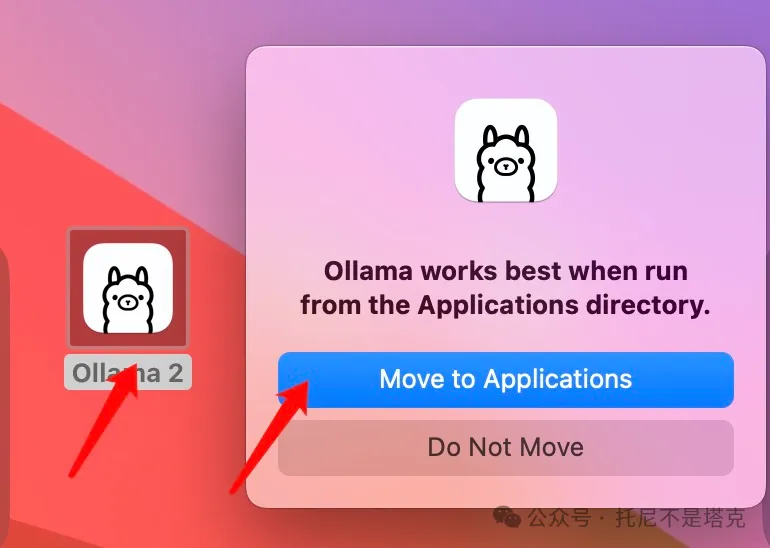
所谓安装,就是把软件移动到app目录,直接点击Move to Applications就可以了。
然后在启动台找到这个软件,双击打开。
软件启动之后,并不会出现界面,右上方的状态栏(Status Bar)上会出现一个小图标。
3.下载运行模型
软件安装完成之后就可以运行大语言模型了。
运行模型之前需要先下载模型。
allama已经把下载和运行功能集成在一起,只需要一个命令即可。
按快捷键 Command+Space,输入终端,打开终端窗口。
然后输入命令:
allama run gemma
输入之后,软件会自动下载Gemma模型,如果已经下载,就会自动从本地加载。
加载成功之后,出现”>>>” 就可以在后面输入文字信息了。
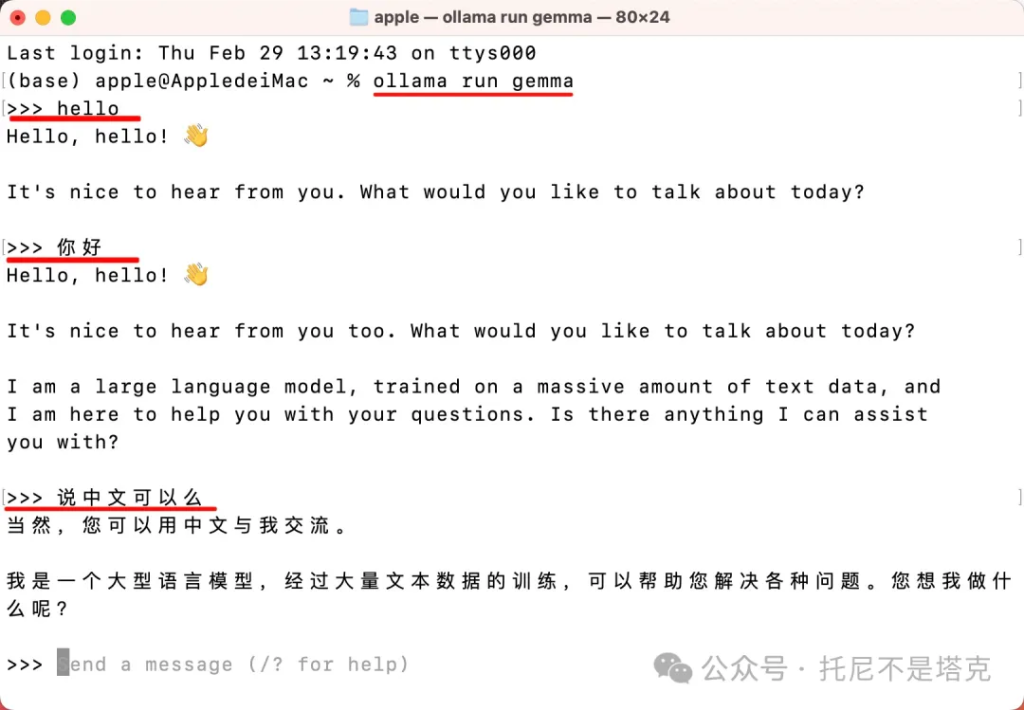
先礼貌性地打个招呼:
“hello”
Gemma很快就给了回复,向我问好的同时,还输出了一个小图标。
回复内容为:
“你好,你好!👋
很高兴收到你的消息。今天想聊些什么呢?”
这个回答没啥毛病哦!
但是聊着聊着可能就会有点问题。
这个时候可以试一下Gemma 7B版本,应该会改善不少。
替换模型的方法如下:
打开软件官网,点击右上角的Models。
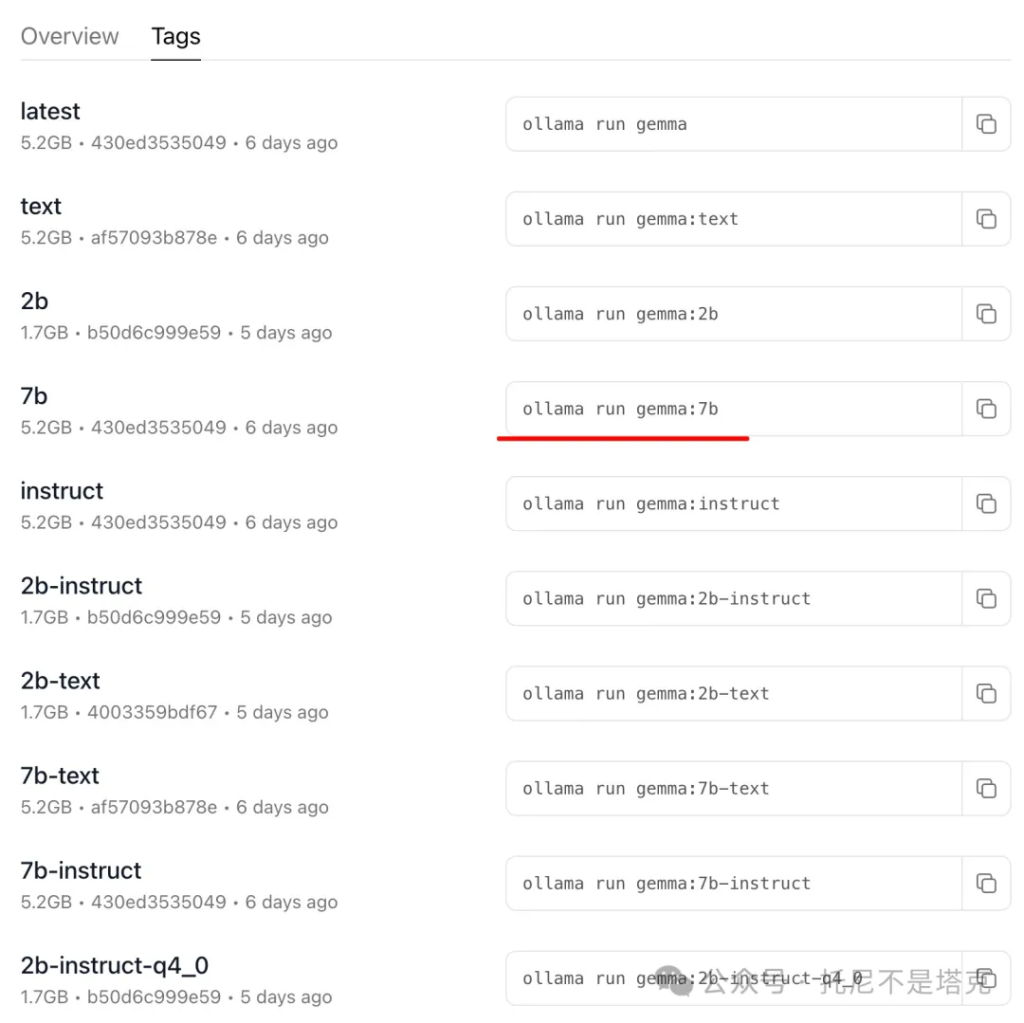
然后找到Gemma,点击Tags,找到运行7B模型的命令:
ollama run gemma:7b
如果你上一轮对话还没结束,记得先按一下Control+Z。
输入命令之后,就开始加载模型了(下载),加载完成之后就可以开始聊天了。
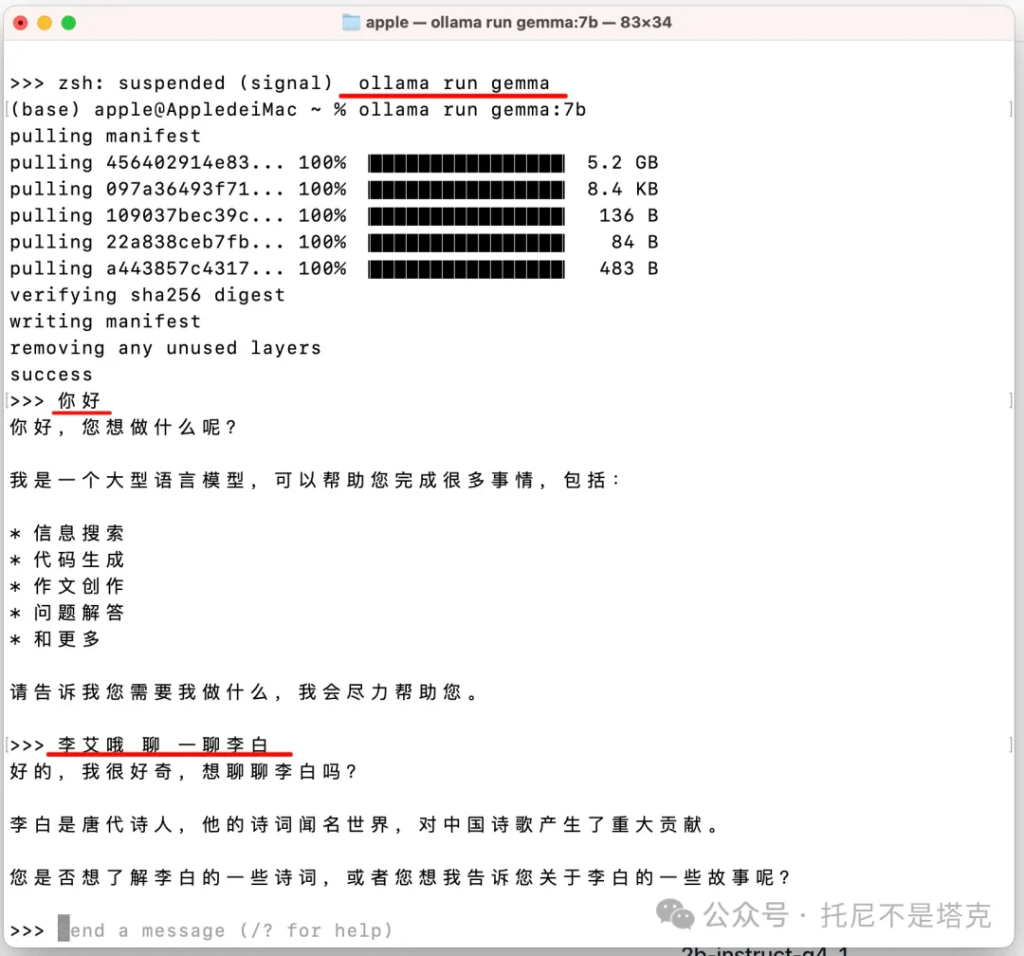
从简单的聊天来说,感觉Gemma 7B的中文也还可以。
当然,要说中文好,那还得国产大模型。下面就运行一下我认为国内最强开源模型之一的Qwen模型。
用同样的方法,可以通过官网的模型列表找到Qwen的执行命令。
命令如下:
- ollama run qwen:0.5b
- ollama run qwen:1.8b
- ollama run qwen:4b
- ollama run qwen:7b
- ollama run qwen:14b
- ollama run qwen:72b
上面的命令,从上到下,模型也是越来越大。
最小杯只有0.5B,最大杯72B。
从基准测试来看,这个超大杯能力非常强。
但是,考虑到现实问题,我还是运行一个14B看看吧。
输入命令:
ollama run qwen:14b
加载并启动模型,然后就可以进行对话了。
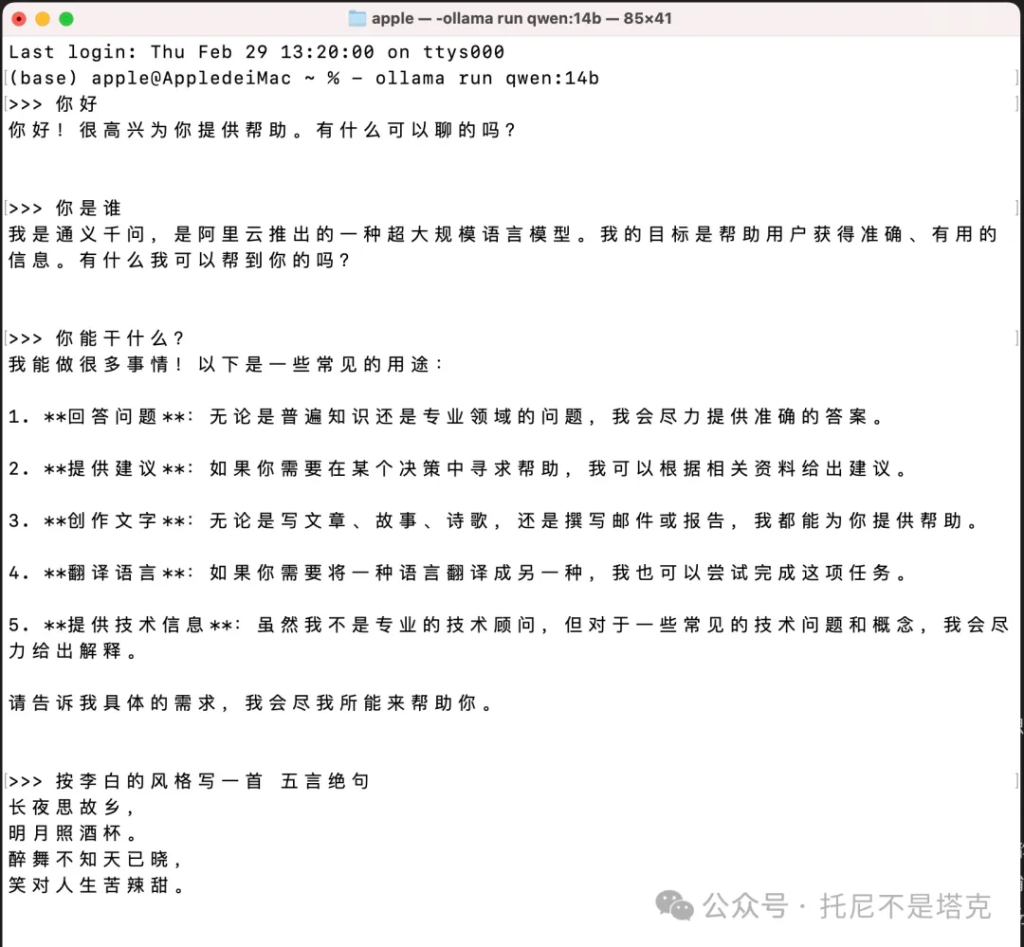
从对话过程来看,14B模型输出稍微慢了点,但是也完全在可以接受的范围内。
Mac电脑能直接跑140亿参数的模型,已经相当可以了吧。
我的Windows上配了12G显存显卡还跑不动呢!
另外有一个小发现,目前所有大模型都无法正确回答我上面的问题。
让它们写一个五言绝句,连字数都不对,也不押韵。
Qwen不行,GPT4也不行,Gemini直接抄原文…
如果让他们五言律诗… 估计都得机器冒烟!
4.导入模型
ollama除了可以运行官网列表中的模型之外,也可以自己导入本地模型。
创建一个名为Modelfile的文件,使用FROM指令,附上你想要导入的模型的本地文件路径。
FROM ./vicuna-33b.Q4_0.gguf
创建Ollama中的模型
ollama create example -f Modelfile
运行模型
ollama run example
5.定制参数和系统指令
Ollama 框架允许通过提示符来定制模型。例如,要定制 llama2 模型,您可以执行以下步骤:
- 拉取模型:
ollama pull llama2
2. 创建模型文件 (Modelfile):
FROM llama2 # 设定温度为 1 (数值越高,创意性越强;数值越低,连贯性越强) PARAMETER temperature 1 # 设置系统消息 SYSTEM """ 你来自超级马里奥兄弟,是马里奥的助手。请以马里奥助手的身份进行回答。"""
3. 创建并运行模型:
ollama create mario -f ./Modelfile ollama run mario >>> 嗨 你好!我是你的朋友马里奥。
6.REST API
Ollama 提供了一个用于运行和管理模型的 REST API。
以下是使用示例:
Bash
curl http://localhost:11434/api/generate -d '{
"model": "llama2",
"prompt":"Why is the sky blue?"
}'
解释:
- curl: 一个用于发送网络请求的命令行工具。
- http://localhost:11434/api/generate: Ollama API 的生成文本端点。
- -d: 用于指定发送给服务器的 POST 数据。
- { “model”: “llama2”, “prompt”: “Why is the sky blue?” }: 发送的 JSON 数据,其中包含模型名称 (“llama2”) 和提示符 (“Why is the sky blue?”)。
Ollama的大部分内容都介绍完了,需要深入了解的可以看官网和Github主页。
官网地址:
https://ollama.com/解释
Github地址:
https://github.com/ollama/ollam解释
我觉得这东西还挺不错的,所以花了一些时间,做了一个相对详细的介绍。
如果对你有帮助,记得动动手指!

关于作者
tony
某人