DragGAN:简介,安装,使用!
下面的这个动图,相信不少人都在网上看到过!
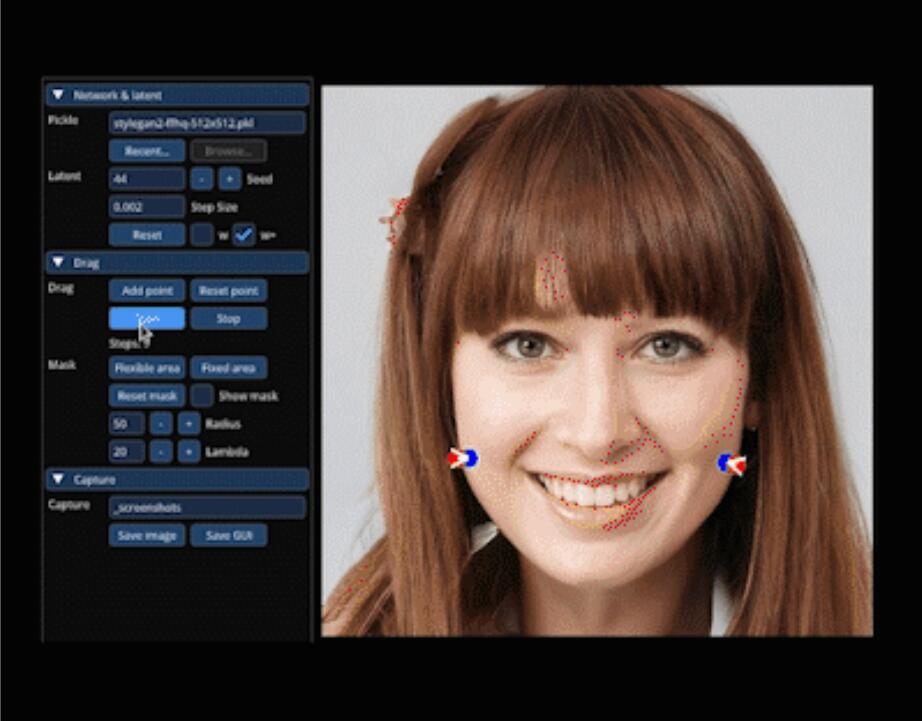 哈哈,此处并不会动,大家看过的自然可以脑补~~~ 说实话,这东西“看起来”确实碉堡了。之前一直都只能看,而现在可以“玩了” ,官方项目依旧更新!但是,要把它玩起来,可能并不轻松。追根溯源,这个其实就是英伟达开源项目StyleGan的衍生项目。
哈哈,此处并不会动,大家看过的自然可以脑补~~~ 说实话,这东西“看起来”确实碉堡了。之前一直都只能看,而现在可以“玩了” ,官方项目依旧更新!但是,要把它玩起来,可能并不轻松。追根溯源,这个其实就是英伟达开源项目StyleGan的衍生项目。
在StableDiffusion没出来之前,这可是最牛逼的图片生成类项目了。四年前,StyleGAN一发布就以其“超清且逼真”的效果惊艳世人。
当时,我的公x号”托尼是塔克”还在,写过一系列文章。时光飞逝,没想到这项目还能老树开花。
说回主题,今天主要是教大家安装DragGAN。
装过Stylegan第一代的人都知道,这东西是真不好装。除了要安装VS,cudnn,cuda,还得修改代码,配置路径….
DragGAN的环境配置几乎和Stylegan3一样!所以安装过程并不会太简单!
今天就来分享一下,我的安装过程,做个记录…
做记录很重要,比如四年前,安装Stylegan的事情,如果不做记录,我今天肯定是想不起来了。
环境介绍:
操作系统:Win11
显卡:RTX3060
辅助软件:CMD,Git,Conda,VS2019,cudnn,cuda
硬件环境其实主要就是显卡,GAN对显卡要求也不低的。不同尺寸模型需要的显存不一样。Rtx3060可以完美驾驭1024×1024,从任务管理的显存消耗来看,单纯运行这个项目,6G显存应该能搞定。
基础软件详细的安装过程,可以参考我之前Stylegan2和Stylegan3的教程,
复制软件全部安装完成之后,就可以进入今天的主题了。
1.获取源代码
因为这是一个开源项目,所以我们需要先获取源代码。源代码的获取方式有两种,一种是命令行,一种是直接下载压缩包。
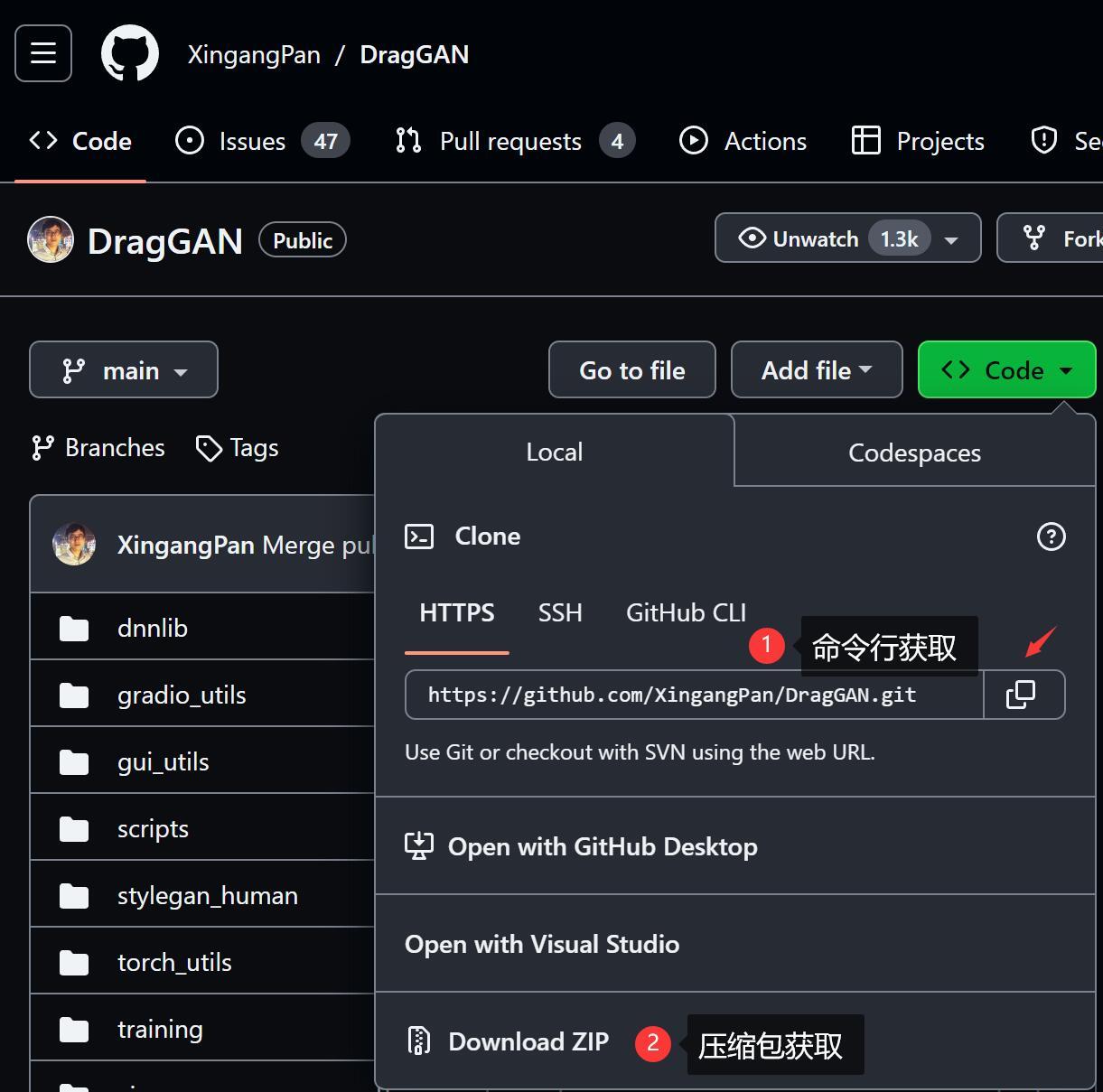
命令行方式
要先确保你安装了GIT工具。
然后就可以在CMD中执行如下命令:
E:cd DEVgit clone https://github.com/XingangPan/DragGAN.git
①切换到E 盘的意思,也可以是D盘,不建议放C盘。
②进入DEV文件夹意思,你可以直接放在某个盘的根目录,就不需要这一行了。
③获取GragGAN的源代码(大部分时候需要魔法)
压缩包获取方式
只要点击Download ZIP就可以直接下载了,一般不用魔法,可以直接下载。下载之后解压到磁盘。比如解压到到E盘下面的DEV文件夹里面。
下载完成之后大概是DragGAN-main.zip这个样子,解压后把后面的“-main” 去掉。这个main还有一个故事,以前叫master,因为不尊重某类人,就改掉了。你们考虑过程序员的感受么…
2. 创建虚拟环境
这是基于Python的项目,所以需要安装Python环境。为了让不同项目,互不影响。所以这里用到了Conda,可以通过这个工具创建独立的Python环境。
在CMD中输入以下命令:
conda create -n draggan python=3.10.6创建成功之后,激活虚拟环境:
conda activate draggan3. 修改配置文件
DragGAN里有一个Conda的依赖文件,可以直接用来创建虚拟环境并安装所有依赖。
conda env create -f environment.yml但是… 这个文件很老了,至少在当前的Windows下安装,会出现一堆问题。比如第一个问题就是找不到cudatoolkit=11.1。
我尝试修改了这个东西,但是依旧会出现其他问题。所以我索性自己写了一个requirements.txt
--extra-index-url https://download.pytorch.org/whl/cu118 numpy==1.23.5 click scipy pillow==9.5.0 requests tqdm==4.65.0 ninja matplotlib torch==2.0.1+cu118 torchvision imageio imgui glfw==2.2.0 pyopengl==3.1.5 imageio-ffmpeg==0.4.3 pyspng gradio
创建requirements.txt并将上面的内容黏贴到里面,将这个文件放在DragGAN 文件夹里面。
然后使用pip安装:
pip install -r requirements.txtpip慢的,可以使用镜像加速。
4. 获取模型
项目官方提供了一个下载模型的sh脚本
sh scripts/download_model.sh但是Windows用户没法直接使用了,最简单的解决方式是在download_model.sh上右键,用记事本打开。
里面有模型的下载地址,直接下载就好了。
下载完成之后放到DragGAN下面的checkpoint文件夹里面,默认没有这个文件夹,可以自己创建。记得把模型文件名改成stylegan2_开头,否则软件无法识别,会报错。
写文章的时候,发现已经更新了一个叫download_model.bat的文件,可以直接运行这个文件来下载模型。
5. 开始运行
按我的方式来,网络通畅的情况,应该不会出什么问题。当然,世界上的问题千千万,我也不能打包票。所以,假设你上面的步骤都完成了。
我们就可以开始激动人心的运行环节了。
项目官方提供的目前还是linux上运行的命令
sh scripts/gui.shWindows的用户可以按下面的方法来运行:
conda activate DragGAN E: cd dev\draggan python visualizer_drag.py checkpoints/stylegan2_dogs_1024_pytorch.pkl
①激活虚拟环境,上面已经做过了,可以不做。
②切换的E盘,上面已经执行了,就不用了。
③进入到项目文件夹
④运行命令启动GUI界面。
启动成功之后,就可以看到“软件”界面了。
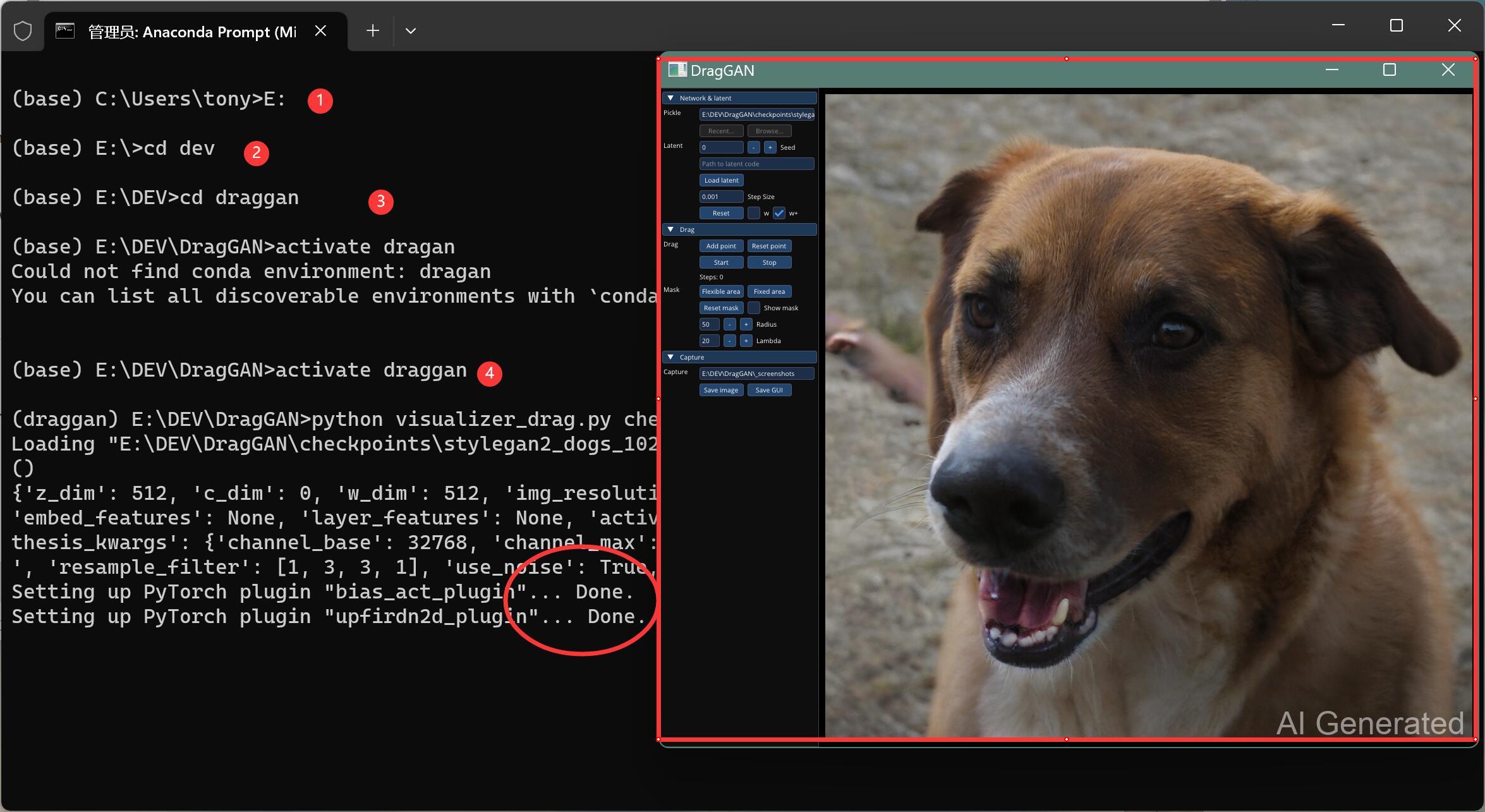
这个时候,只要在狗子脸上点两下,然后点击左边的Start就可以了。
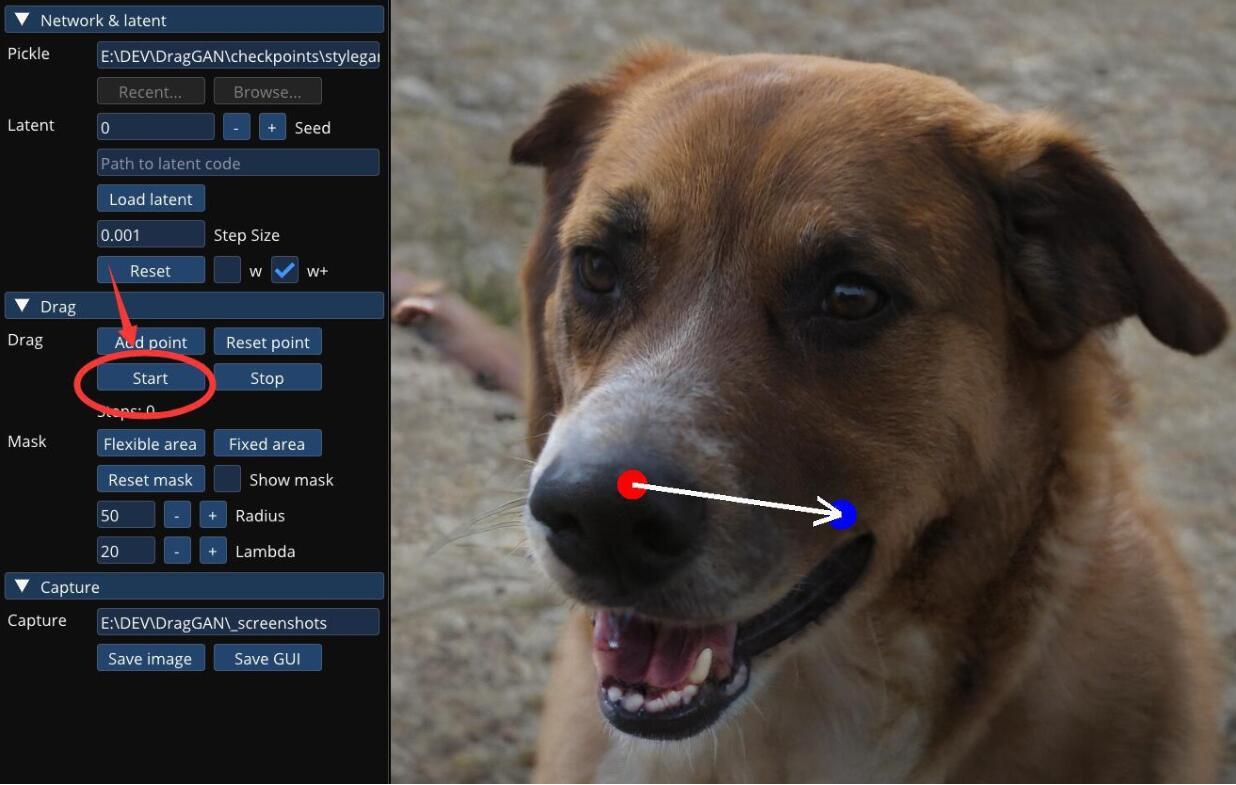
很快,狗子就会“正视”你了。哈哈~
用这个GUI动态效果还是挺酷的。但是菜单比较小,而且有一些BUG,点到有些地方会直接崩溃,切换模型也不是很方便。
所以,我们可以启动一下WebUI
python visualizer_drag_gradio.py运行之后,输出如下:
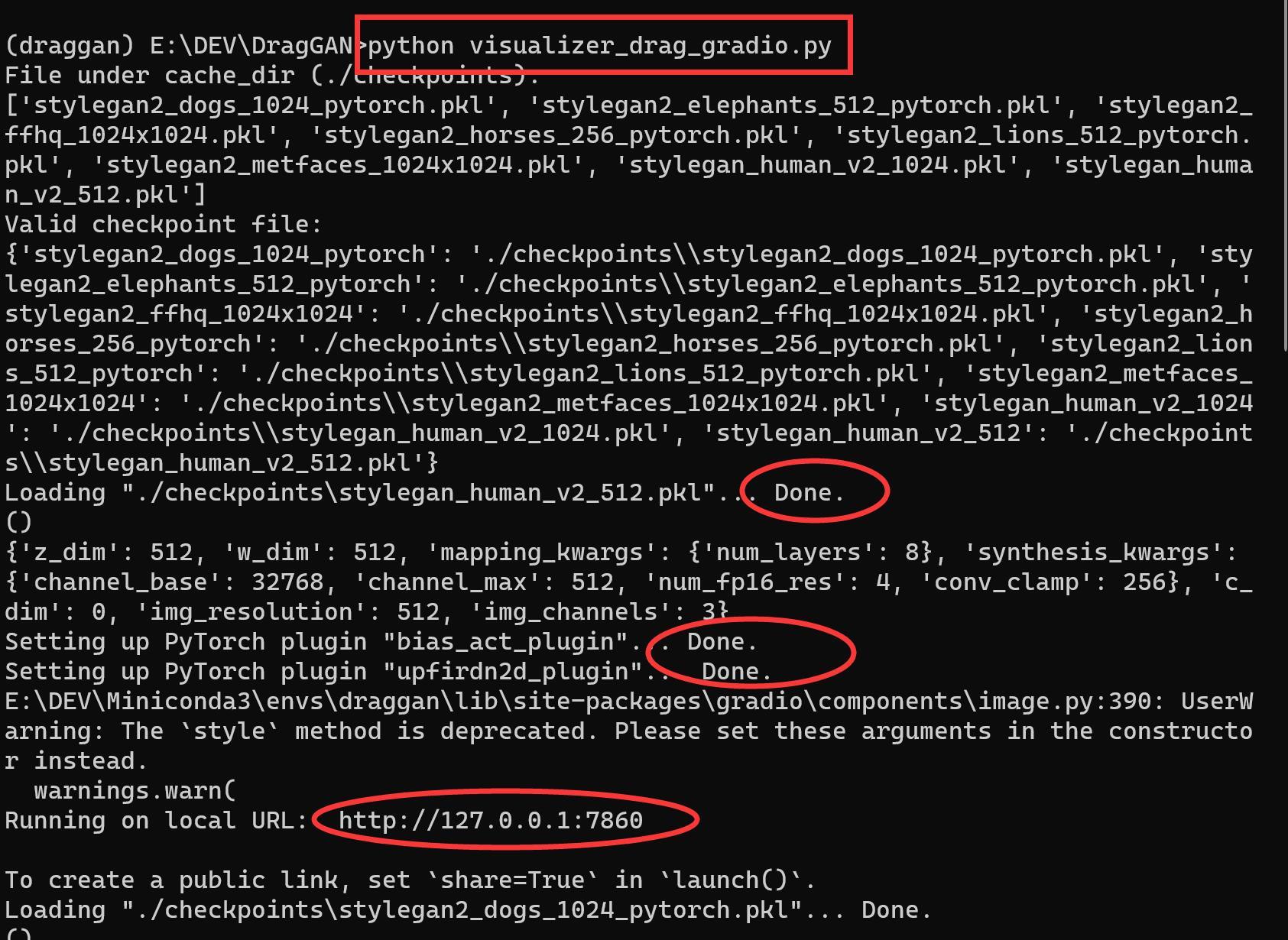
当看到各种done,然后看到一个http的网址之后,就说明启动正常了。
把网址复制到浏览器,打开,就可以再次见到我们的个狗子了。
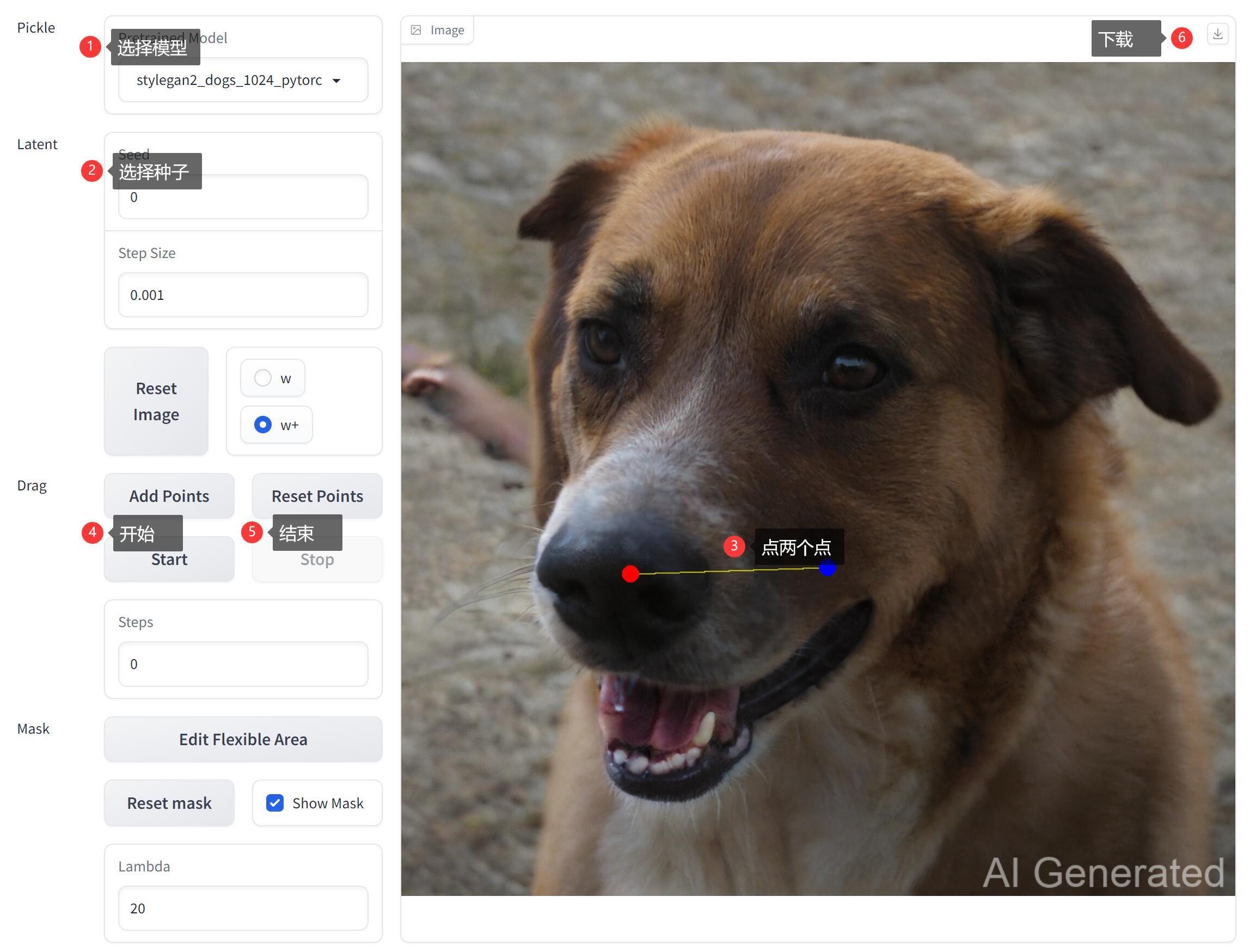
使用步骤:
① 选择模型,所有checkpoints下面的模型都会显示在这里。
② 选择种子,一个种子对应一条不同的狗子。大概有几十亿,没记错的话。
③ 在图片上点两下,红色会起点,蓝色为终点。
④ 开始拖拽,狗鼻子会慢慢往蓝色点靠。
⑤ 结束运行,你觉得差不多了直接点击结束就好了。网页版有点小问题,不点会运算很久很久。
⑥ 下载图片,如果有必要保存图片,可以点击下载。
注意点,WebUI默认会加一个叫stylegan_human_v2_512.pkl 的人类模型。所以需要先将这个模型放到checkpoint文件夹。当然,你懂代码话,也可以把默认的改成狗子模型,那么不用去下载另外的模型了。
另外,WebUI版,动态效果,没有本地GUI好。最终结果是一样的。
接下来,就由大家自由探索了。Stylegan的模型,都可以用在这里。这几年已经积累下很多模型。
其中质量比较好的,还是得数英伟达官方的FFHQ1024x1024。
另外发现一个叫human的模型,也不错。
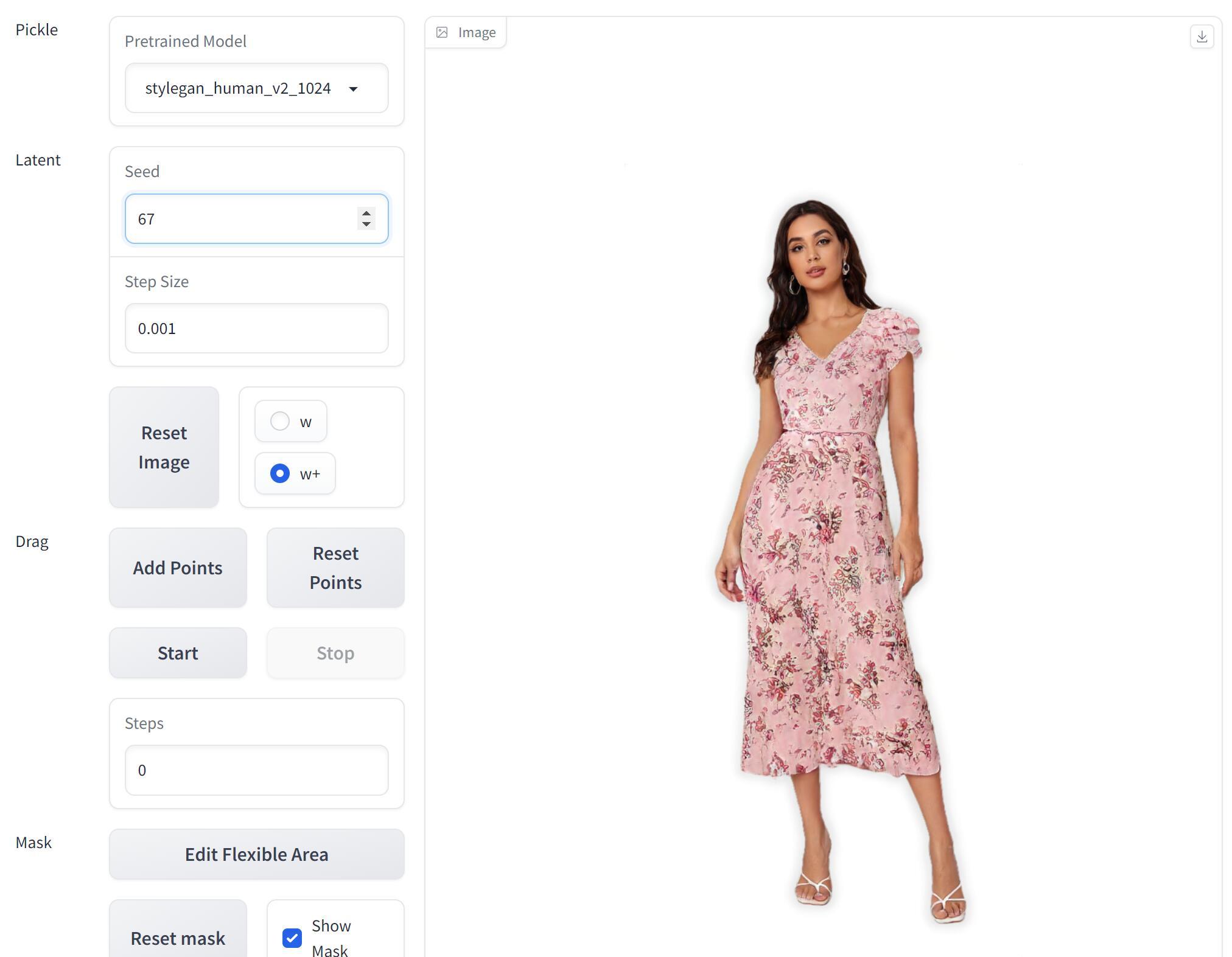
可以生成不同的人穿着不同衣服的图片。记得用1024×1024的模型,有些图片也是有明显缺陷的,有些看起来还不错。
看别人的动态图,可能期待值拉的很满,但是,要明白一点,卖家秀和买家秀肯定不一样的。这个项目目前并没有看到太大实用性。很多时候生成和调整的效果都差强人意。
另外,我敢肯定,很多人都以为小视频中的图片是“真的图片”。以为直接选一张照片,就能开始点点P图了。其实并不是,上面的图片都是由模型直接生成的。
你可以用这个项目来生成无限多的某类图片。
但是,如果你想P现实的中的图片,可没有那么容易….你需要用到其他技术。先把这个图片投射到Stylegan宇宙中,然后再进行无法无天的摆弄。
除此这些不足和预期差异之外,这个项目还是挺好玩的!
至少,这个项目把StyleGAN的使用可视化了,而且可以快速接入各种各样的模型,有能力的也可以自己训练模型…. 如果你有这财力的话…
据说Styelgan2,整个项目花费了51个GPU年,总耗电量131.61MWh。也就是单个Tesla V100 GPU需要51年,总耗电量13万度,单电费10万块钱。(来自知乎)
其实,可以微调!哈哈~~ 给你们看看我压箱底的大宝贝!
为了我丢失的丹,点个赞吧~~!!
相关链接:
GragGAN:
https://github.com/XingangPan/DragGAN
Stylegan2手把手教安装!
Stylegan3手把手教安装!
CMD基础教程
Git基础教程
Conda基础教程



关于作者
tony
I am nobody !