英伟达ChatWithRTX最新版安装过程全记录!
ChatWithRTX是由NVIDIA开发的大型语言模型聊天机器人,刚发布那阵子,我安装过一次。

但当时还是beta,最近去看了一眼,好像又更新过了。所以我准备重新装一次,做一个完整的记录。
重点提示,这个版本可以做到比较彻底离线使用。另外,准备把切换中文模型这个攻略给补上!
为了照顾到第一次接触这个东西的人,开始之前做一点小介绍。
ChatWithRTX是什么?
ChatWithRTX是英伟达给大家做的演示程序。
这个程序结合大语言模型(LLM)来进行基于本地文档的检索和问答。
使用了检索增强生成(RAG)、TensorRT-LLM 和 RTX 加速等技术。
可以独立在个人电脑或者工作站上使用,不依赖在线接口,主打一个安全和快速!
Chat with RTX 支持各种文件格式,包括文本、pdf、doc/docx 和 xml。只需将应用程序指向包含文件的文件夹,它就会在几秒钟内将它们加载到库中。
为什么要用ChatWithRTX?
强大的大语言模型现在已经非常之多,比如GPT4,Gemini,还有最近很火的Kimi。他们能力都很强,都能对文档进行分析。为啥还要装个ChatWithRTX这样的东西?
简单来说,主要是基于以下几点:
- 快速
- 安全
- 自主可控~~哈哈
- 可以DIY
云端产品用起来是爽啊,但是除了要不断充值 ,还完全不可控。
本地搞一个,爱咋咋滴,爽得很。
充分发挥去中心化思想“ALL IN PC”。
对喜欢研究技术的人来说,当然是可以自己拿来玩一下,自己装的就是特别香啊。
ChatWithRTX怎么用?
前面的内容,只是为了让文章不那么晦涩难懂,下面就直接上干的了!
接下来就完整记录下安装过程,说一说注意点。
另外强调一下这个版本的软件,可以无ti安装,最多设置一个PIP镜像就可以了,其他东西都可以做到完全离线。
1.获取软件压缩包
安装软件自然要先获取软件,获取方式很简单,直接到官方主页去下载。
主页地址:
https://www.nvidia.com/en-in/ai-on-rtx/chat-with-rtx-generative-ai/下面是我下载已经下载的三个版本。
文件有点大,基本在35G左右,可以用IDM或者迅雷之类辅助一下。
目前最新的版本是35结尾那个。
2.解压
使用任意解压软件解压,推荐使用7z,解压过程无需C盘缓存。
解压后发现文件夹名称里有3_27的标识,估计是3月27日发布的意思。
解压完的文件也巨大,记得准备足够的空间。
3.安装
解压完成之后,直接点击setup.exe开始安装。
安装过程非常简单,点几下就好了。
为啥推荐CWR,主要是安装真的很简单。
整体感觉和安装驱动差不多。
显示系统检测(System Check)
点击同意并继续(Agree and Continue)
然后下一步到安装选项。
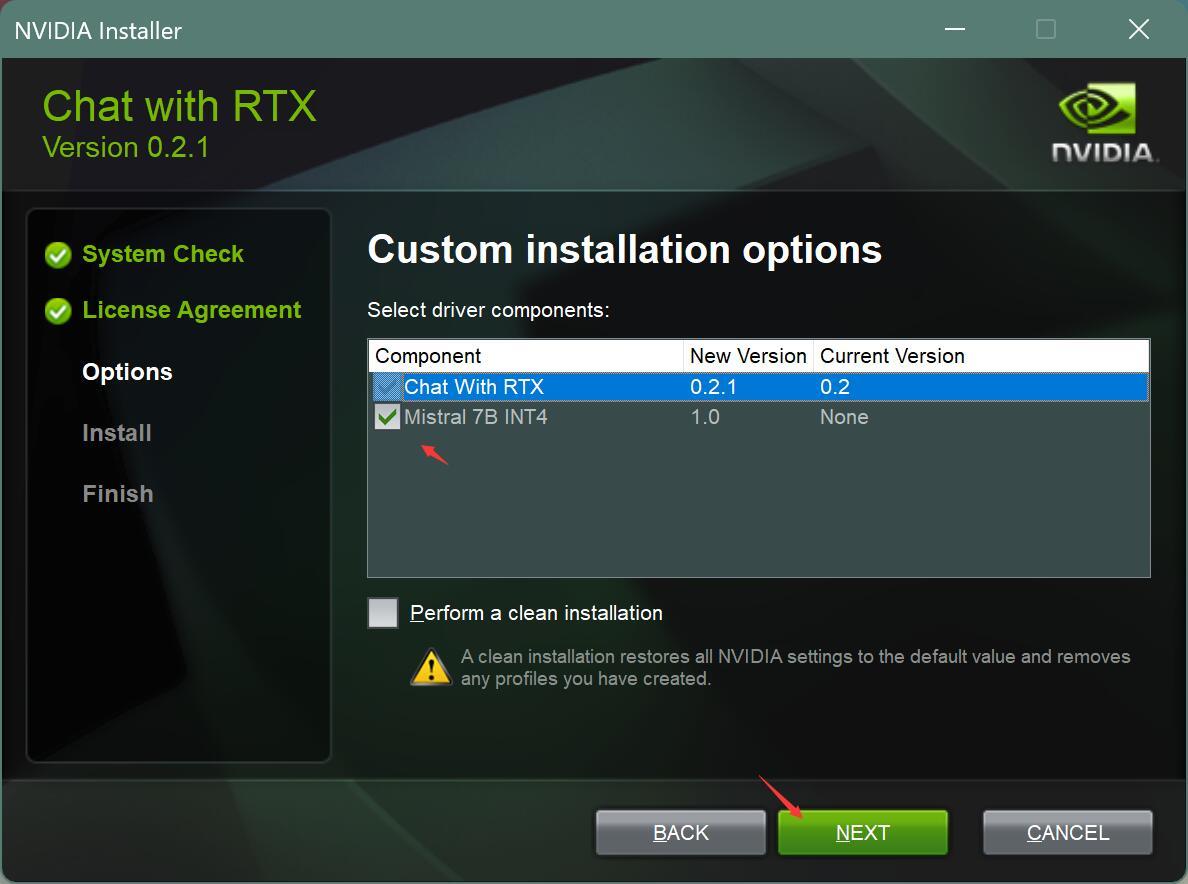
这里需要勾选一下Mistral 7B INT4 这个模型,点击下一步(NEXT)。如果你的显存大于16,这里应该还有一个Llama可以勾选。
设置安装路径。
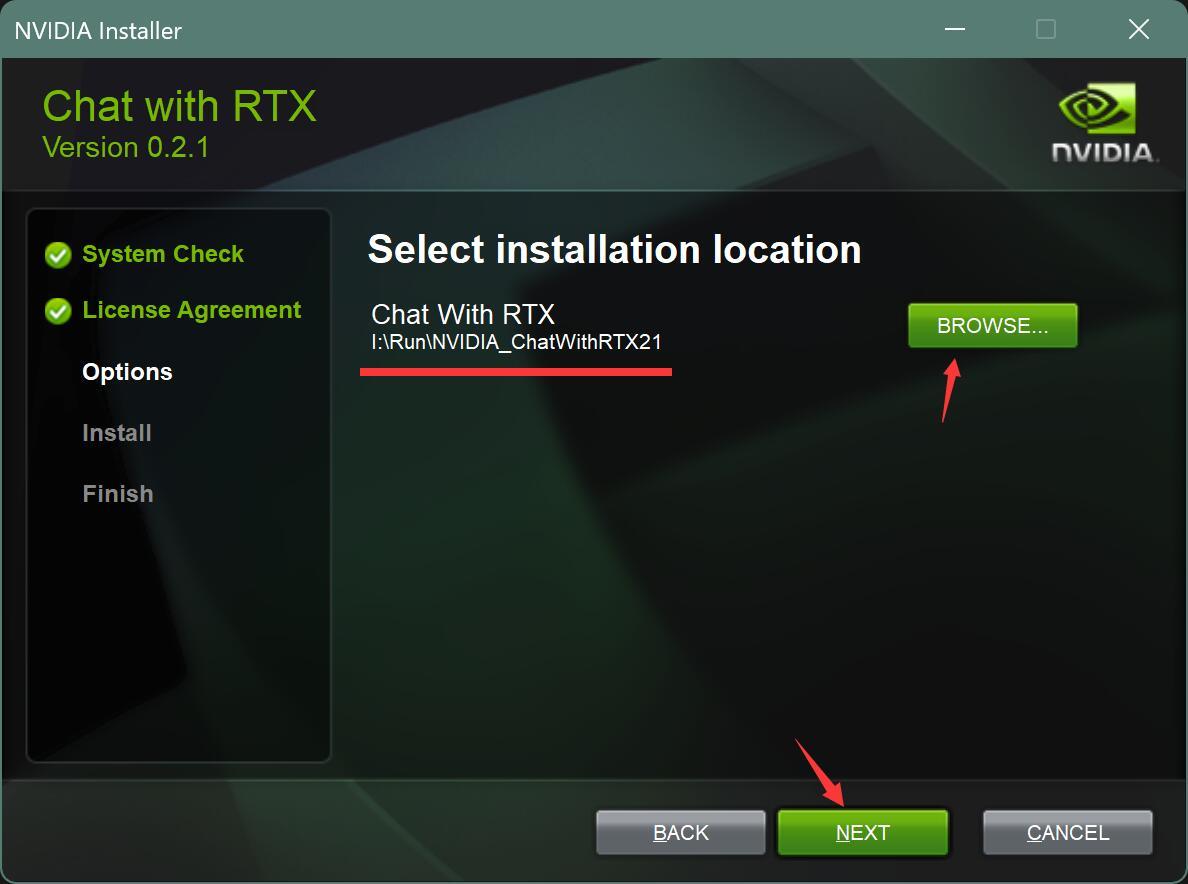
由于文件比较大,最好不要装C盘,选择一个比较大的空间。点击下一步。
等待安装。
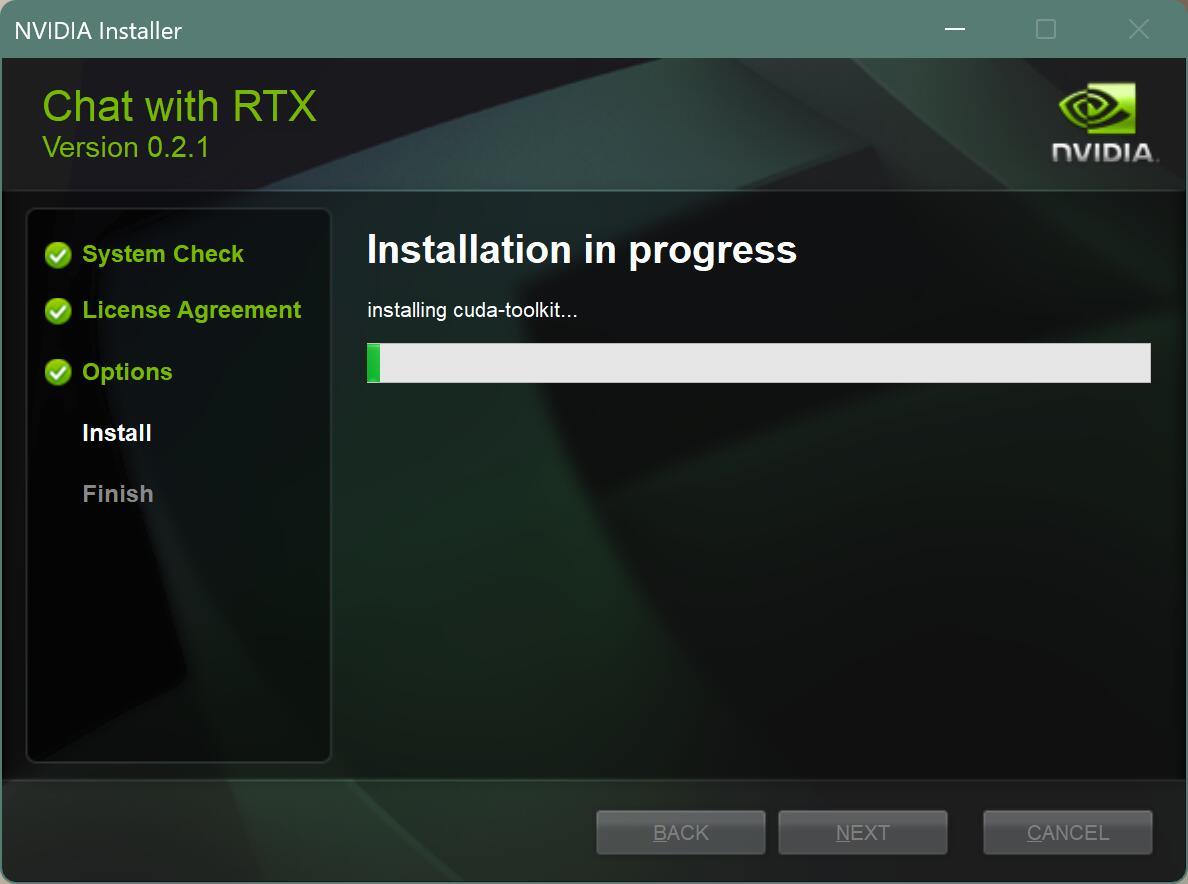
接下来就是全自动安装,你只要等就好了。
我看了一下安装过程,大概有如下操作。
- 缓存文件
- 安装miniconda
- 创建虚拟环境
- 安装 cuda-toolkit
- 联网下载依赖并安装
- 安装Mistral 7B INT4模型
- 构建Mistral 7B INT4引擎
安装成功后界面如下:
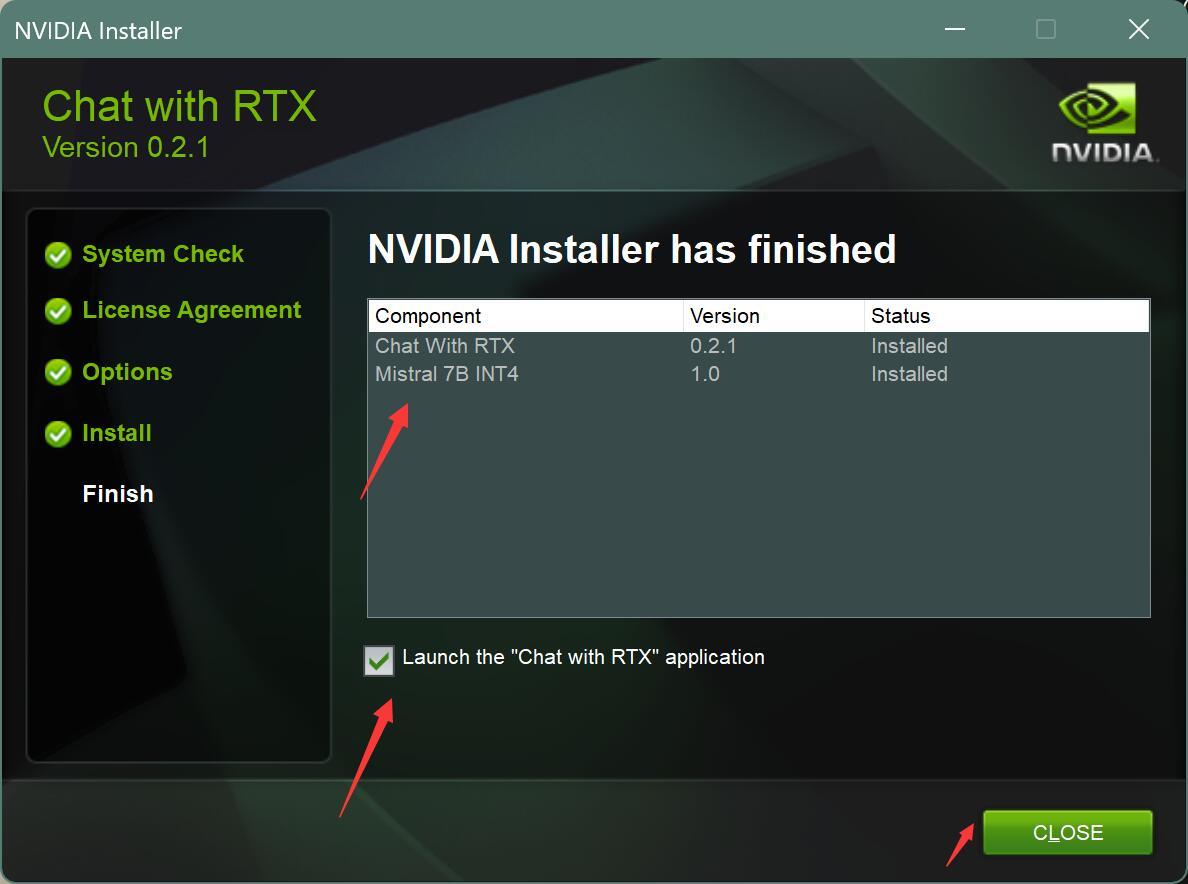
我第一次安装失败了,不清楚原因。后来重新装了一次成功了,并没有做任何多余操作。
这一步消耗的时间大概在10分钟左右,中途会联网,但是并不需要魔法工具。
考虑到要联网安装pip依赖,所以最好是本地配置一下pip镜像。
4.使用
点击Close关闭安装界面之后,桌面会多一个快捷方式,并自动运行软件。
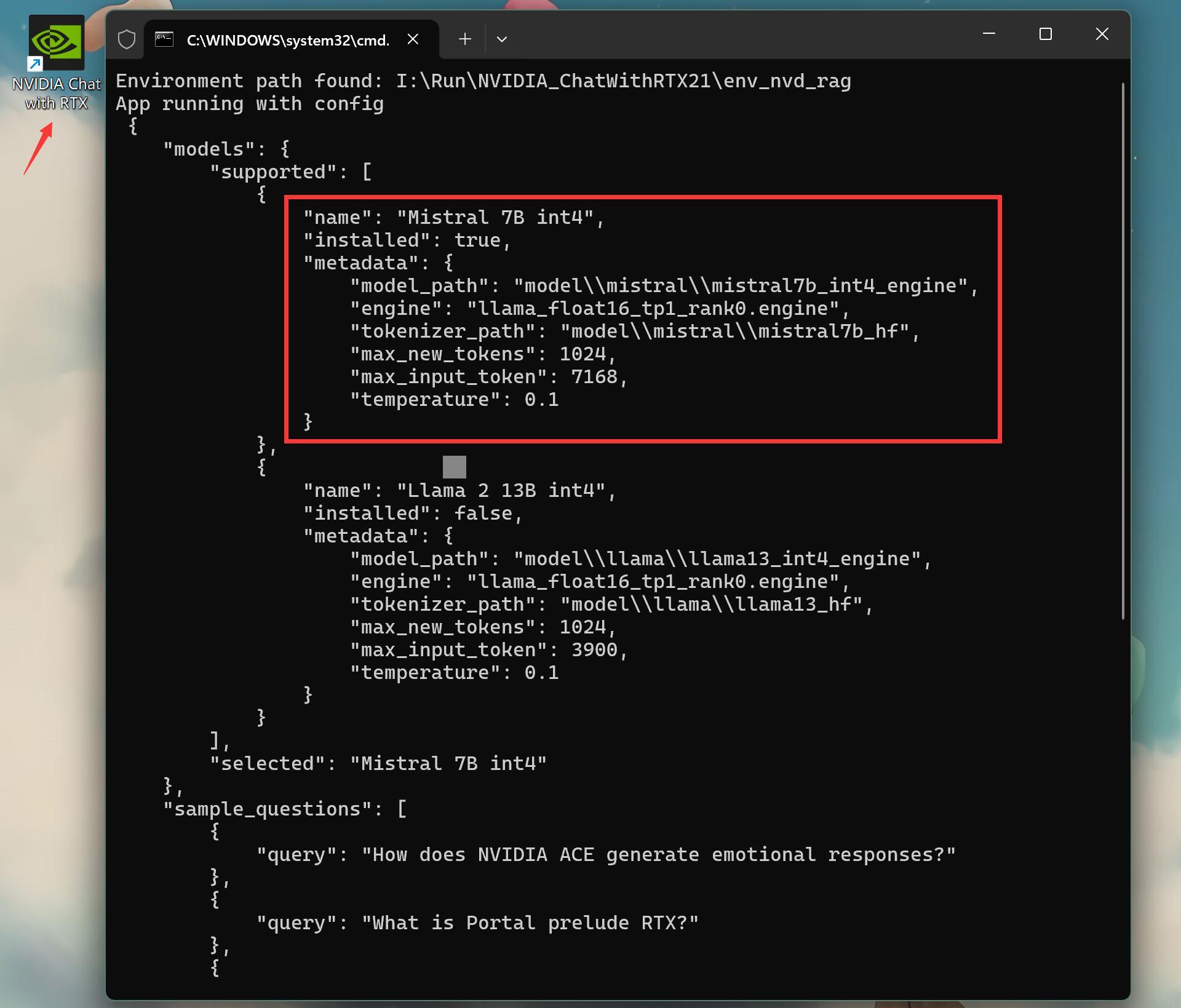
运行软件之后会自动读取配置文件,并启动webui,打开浏览器。
打开之后界面如下:
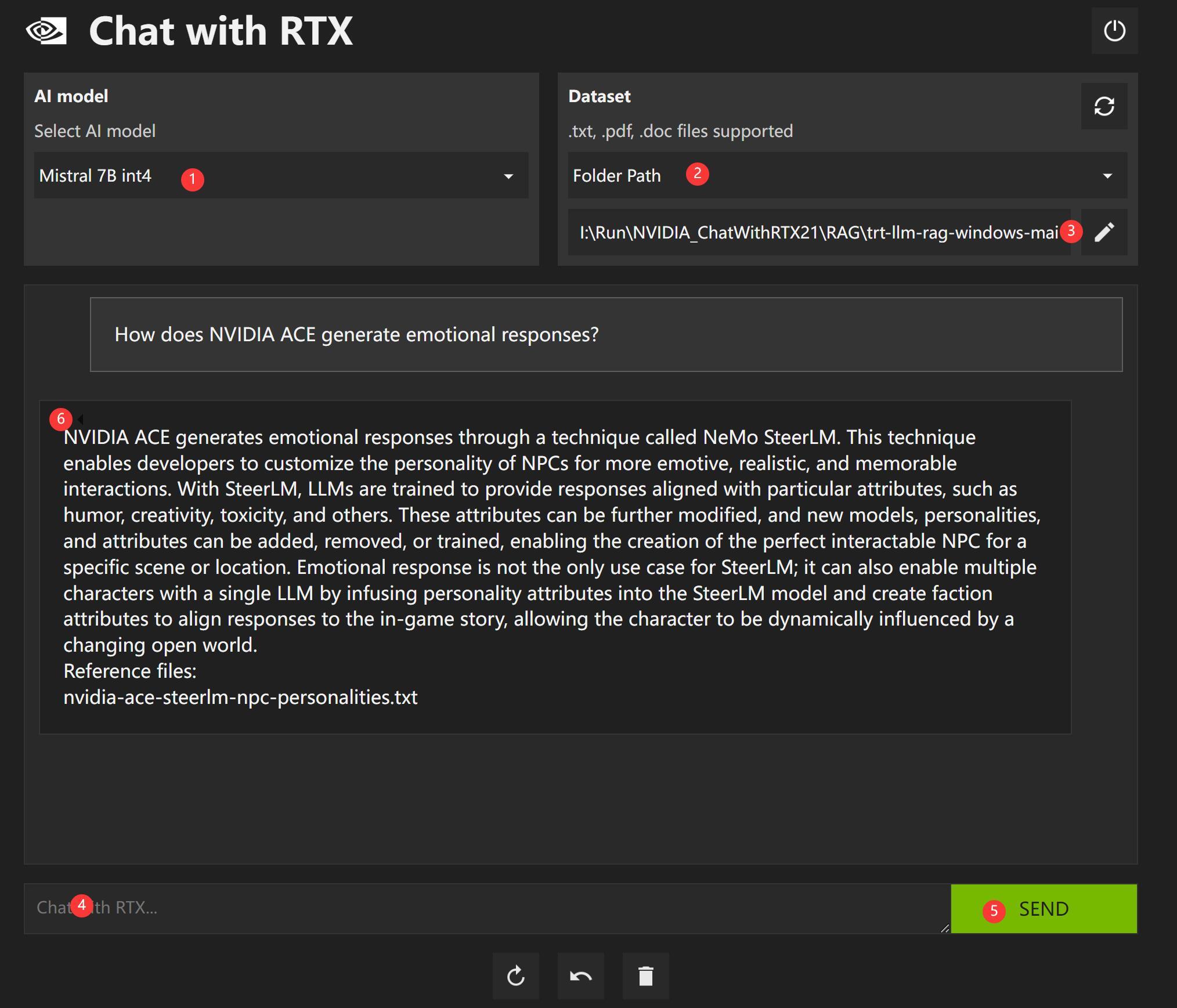
默认选择模型是① Mistral 7B int4,模式为本地检索②,路径为本地一个文件夹③
选择或者输入一个问题④,点击Send⑤,就可以使用大模型,根据提问来快速检索本地文件里的内容了。
界面上还有一些刷新,回撤,删除,关闭的按钮。
③处比较关键,这里指定了本地文档的路径。软件默认指向了自带的一个dataset文件夹,文件夹里放了几十个英文文件。
我们可以修改这个路径,指向我们自己的文档所在的文件夹,比如mydataset。修改路径后,会有一个生成vector_embedding的过程,生成之后会保存在一个叫mydataset_vector_embedding的文件夹里面。
你每次修改了本地文档之后,记得点击一下右上角的刷新,重新生成这个文件夹。
当然,除了检索功能之外,也可以切换为单纯的对话模式。
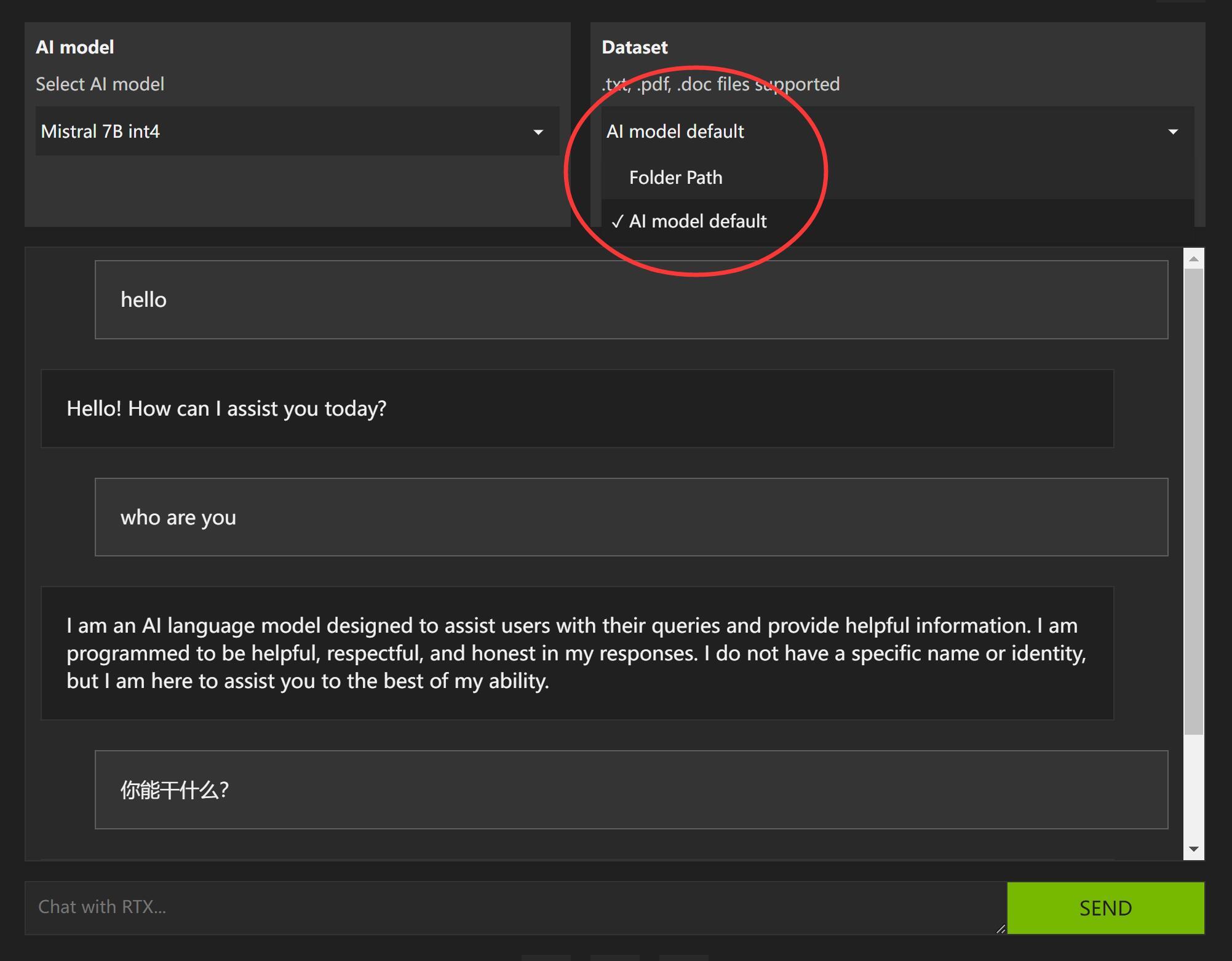
观察发现,在线分析youtube视频内容的选项已经没了。
5. 安装Llama2
另外,可以看到,这里的模型只有一个。其实本身应该有两个,还有一个Llama2。
因为我的电脑显卡显存只有12G,所以没有给我装上了。
如果你也是12G显存,但是想要用Llama,
可以修改一下llama13b.nvi这个文件。
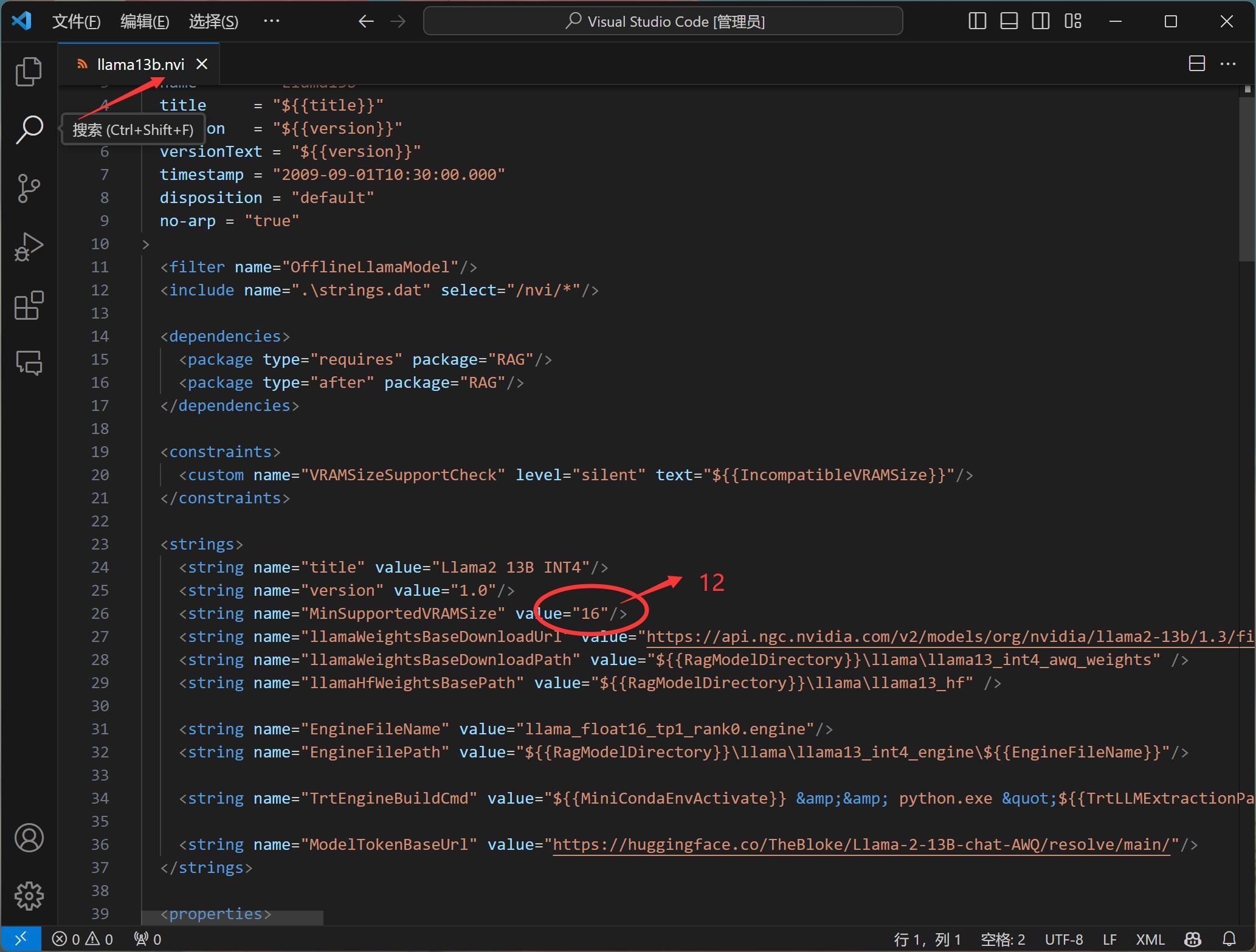
就是把图片中红色圈中的内容,修改为12即可。
修改完成之后,重新点击setup安装一次,就搞定了。
到这里ChatWithRTX的安装就完了。
安全完成之后,只要点击快捷方式启动软件,启动之后就能快速使用了。
大语言模型加持下,做完全离线的本地检索非常不错。
这种搜索方式明显要强于谷歌百度的传统检索关键词检索模式(太辣鸡了)。
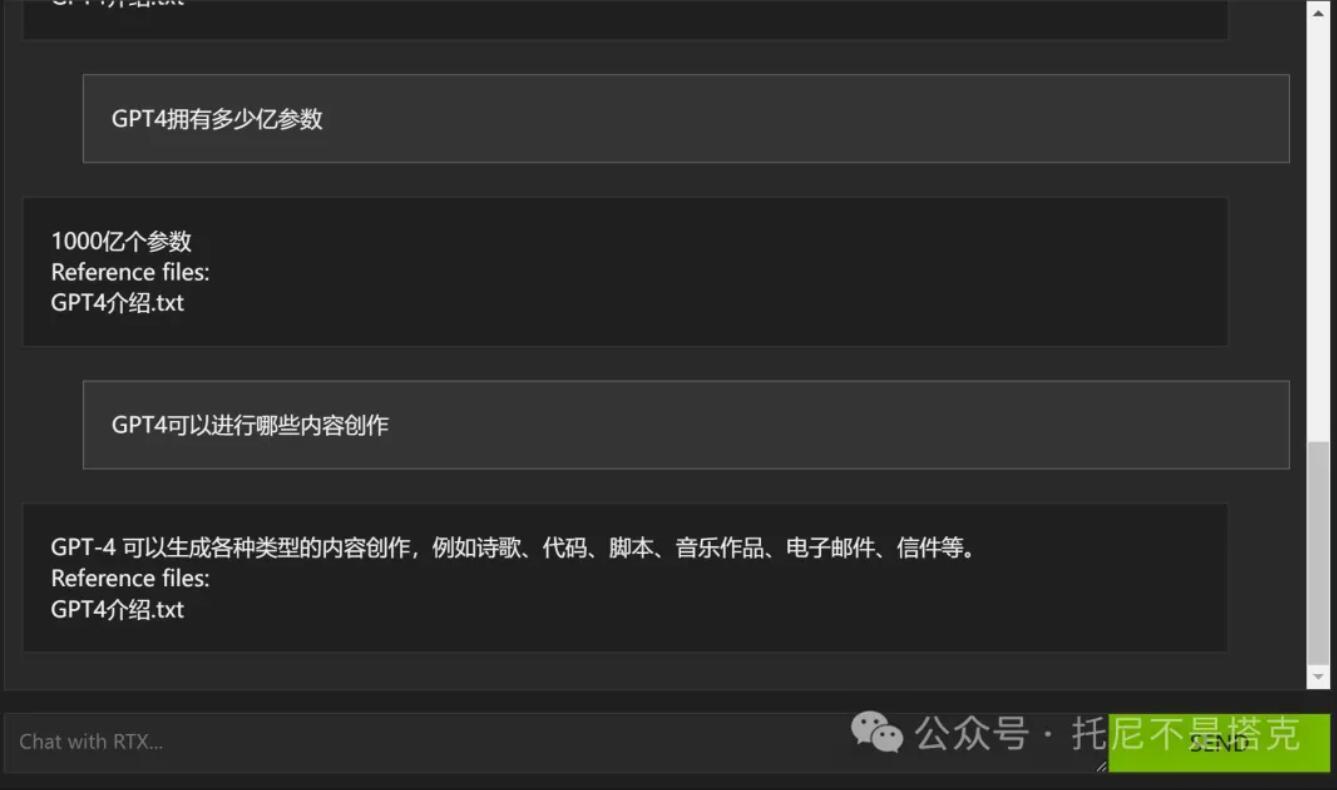
可以根据自己的数据库,做出基于语义的检索,获取精准和简练的回答。
这就相当于,自己电脑上有个小号GPT,并且有个小而强的搜索引擎了。
当然,这里还有一个问题,默认的两个大语言模型为英文模型,这对中文用户非常不友好!
所以,换一个中文模型非常有必要。
我之所以在那么多天后重新写这篇文章,就是为了把这一点补充完整。
限于篇幅,单独起一篇!
下次见!



关于作者
tony
I am nobody !