好消息啊,GLM-4 竟然开源了!
GLM是第一批开源的中文模型,在各方面表现都非常出色,经过多轮迭代,已经更新到GLM-4。 GLM-4 已经非常强大可以和顶级模型PK,所以一开始智谱AI并没有将其开源。

好消息是,现在CLM-4开源了,所有人都可以装进自己的电脑,玩起来了。
下面来具体看一下这个开源项目。
主要功能和特点
- 模型性能:在语义、数学、推理、代码和知识等数据集评测中,GLM-4-9B及其对齐版本GLM-4-9B-Chat表现优于Llama-3-8B。
- 高级功能:GLM-4-9B-Chat支持多轮对话、网页浏览、代码执行、自定义工具调用和长文本推理,最大支持128K上下文长度。
- 多语言支持:支持包括日语、韩语、德语在内的26种语言。
- 长文本支持:GLM-4-9B-Chat-1M模型支持1M上下文长度,约200万中文字符。
- 多模态支持:基于GLM-4-9B的多模态模型GLM-4V-9B,具备1120×1120高分辨率下的中英双语多轮对话能力,在中英文综合能力、感知推理、文字识别和图表理解等多方面表现卓越,超越多个现有先进模型。
模型列表
- GLM-4-9B:基本模型,支持8K上下文长度。
- GLM-4-9B-Chat:对话模型,支持128K上下文长度。
- GLM-4-9B-Chat-1M:对话模型,支持1M上下文长度。
- GLM-4V-9B:多模态模型,支持8K上下文长度。
评测结果
GLM-4-9B和GLM-4V-9B在多项评测中表现优异,包括对话模型典型任务、基座模型典型任务、长文本能力、多语言能力和工具调用能力。
对话模型典型任务
|
Model |
AlignBench |
MT-Bench |
IFEval |
MMLU |
C-Eval |
GSM8K |
MATH |
HumanEval |
NaturalCodeBench |
|
Llama-3-8B-Instruct |
6.40 |
8.00 |
68.6 |
68.4 |
51.3 |
79.6 |
30.0 |
62.2 |
24.7 |
|
ChatGLM3-6B |
5.18 |
5.50 |
28.1 |
66.4 |
69.0 |
72.3 |
25.7 |
58.5 |
11.3 |
|
GLM-4-9B-Chat |
7.01 |
8.35 |
69.0 |
72.4 |
75.6 |
79.6 |
50.6 |
71.8 |
32.2 |
基座模型典型任务
|
Model |
MMLU |
C-Eval |
GPQA |
GSM8K |
MATH |
HumanEval |
|
Llama-3-8B |
66.6 |
51.2 |
– |
45.8 |
– |
33.5 |
|
Llama-3-8B-Instruct |
68.4 |
51.3 |
34.2 |
79.6 |
30.0 |
62.2 |
|
ChatGLM3-6B-Base |
61.4 |
69.0 |
26.8 |
72.3 |
25.7 |
58.5 |
|
GLM-4-9B |
74.7 |
77.1 |
34.3 |
84.0 |
30.4 |
70.1 |
长文本
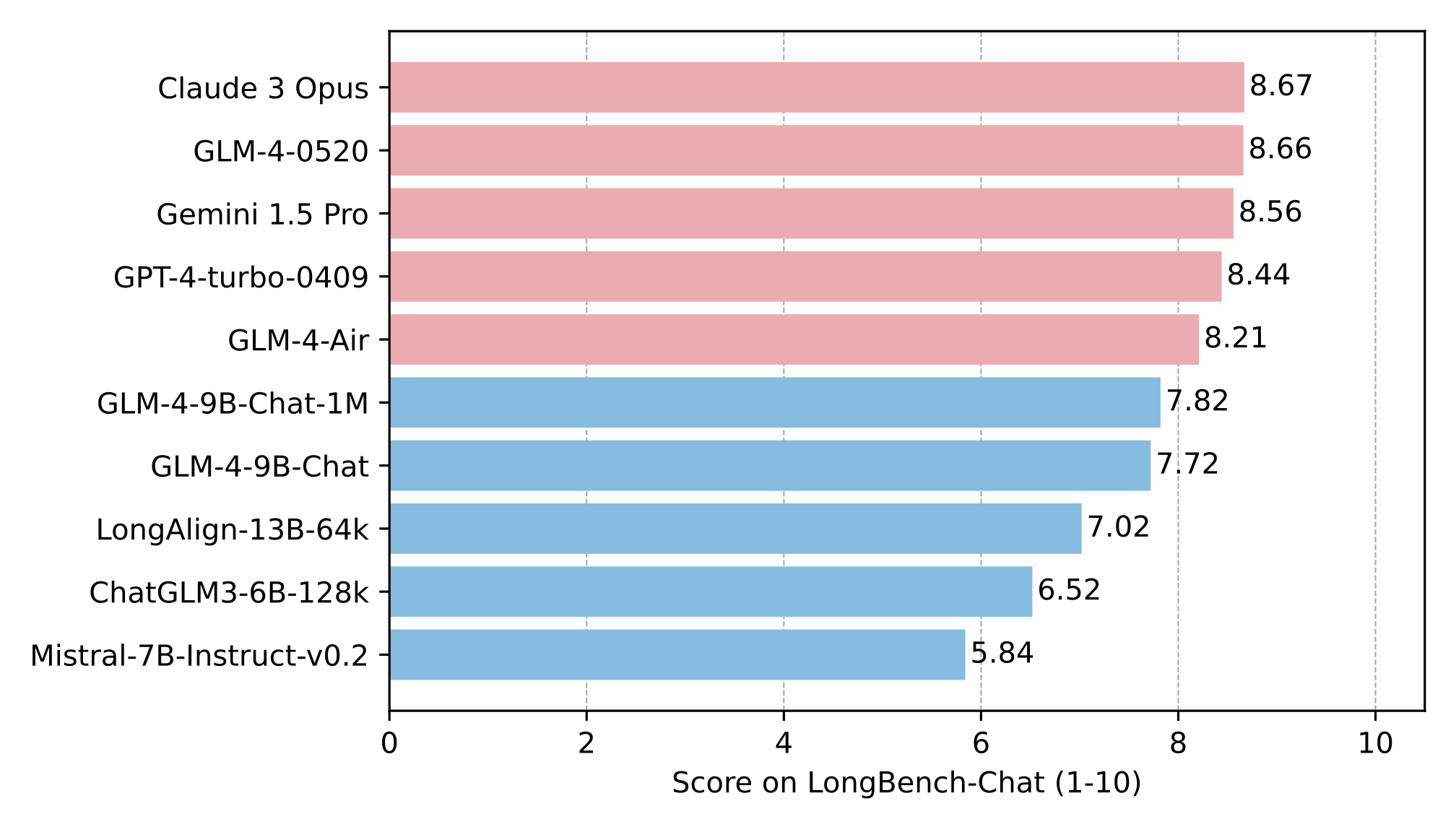
多语言能力
|
Dataset |
Llama-3-8B-Instruct |
GLM-4-9B-Chat |
Languages |
|
M-MMLU |
49.6 |
56.6 |
all |
|
FLORES |
25.0 |
28.8 |
ru, es, de, fr, it, pt, pl, ja, nl, ar, tr, cs, vi, fa, hu, el, ro, sv, uk, fi, ko, da, bg, no |
|
MGSM |
54.0 |
65.3 |
zh, en, bn, de, es, fr, ja, ru, sw, te, th |
|
XWinograd |
61.7 |
73.1 |
zh, en, fr, jp, ru, pt |
|
XStoryCloze |
84.7 |
90.7 |
zh, en, ar, es, eu, hi, id, my, ru, sw, te |
|
XCOPA |
73.3 |
80.1 |
zh, et, ht, id, it, qu, sw, ta, th, tr, vi |
工具调用能力
|
Model |
Overall Acc. |
AST Summary |
Exec Summary |
Relevance |
|
Llama-3-8B-Instruct |
58.88 |
59.25 |
70.01 |
45.83 |
|
gpt-4-turbo-2024-04-09 |
81.24 |
82.14 |
78.61 |
88.75 |
|
ChatGLM3-6B |
57.88 |
62.18 |
69.78 |
5.42 |
|
GLM-4-9B-Chat |
81.00 |
80.26 |
84.40 |
87.92 |
多模态能力
|
|
MMBench-CN-Test |
SEEDBench_IMG |
MMStar |
MMMU |
MME |
HallusionBench |
AI2D |
OCRBench |
OCRBench |
|
gpt-4o-2024-05-13 |
83.4 |
82.1 |
77.1 |
63.9 |
69.2 |
2310.3 |
55.0 |
84.6 |
736 |
|
gpt-4-turbo-2024-04-09 |
81.0 |
80.2 |
73.0 |
56.0 |
61.7 |
2070.2 |
43.9 |
78.6 |
656 |
|
gpt-4-1106-preview |
77.0 |
74.4 |
72.3 |
49.7 |
53.8 |
1771.5 |
46.5 |
75.9 |
516 |
|
InternVL-Chat-V1.5 |
82.3 |
80.7 |
75.2 |
57.1 |
46.8 |
2189.6 |
47.4 |
80.6 |
720 |
|
LLaVA-Next-Yi-34B |
81.1 |
79.0 |
75.7 |
51.6 |
48.8 |
2050.2 |
34.8 |
78.9 |
574 |
|
Step-1V |
80.7 |
79.9 |
70.3 |
50.0 |
49.9 |
2206.4 |
48.4 |
79.2 |
625 |
|
MiniCPM-Llama3-V2.5 |
77.6 |
73.8 |
72.3 |
51.8 |
45.8 |
2024.6 |
42.4 |
78.4 |
725 |
|
Qwen-VL-Max |
77.6 |
75.7 |
72.7 |
49.5 |
52.0 |
2281.7 |
41.2 |
75.7 |
684 |
|
Gemini 1.0 Pro |
73.6 |
74.3 |
70.7 |
38.6 |
49.0 |
2148.9 |
45.7 |
72.9 |
680 |
|
Claude 3 Opus |
63.3 |
59.2 |
64.0 |
45.7 |
54.9 |
1586.8 |
37.8 |
70.6 |
694 |
|
GLM-4V-9B |
81.1 |
79.4 |
76.8 |
58.7 |
47.2 |
2163.8 |
46.6 |
81.1 |
786 |
快速调用方法
可以使用Transformers后端或vLLM后端进行推理,详细代码示例和硬件配置要求请参考项目的GitHub页面。
快速调用 GLM-4-9B-Chat
使用 transformers 后端进行推理:
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
device = "cuda"
tokenizer = AutoTokenizer.from_pretrained("THUDM/glm-4-9b-chat", trust_remote_code=True)
query = "你好"
inputs = tokenizer.apply_chat_template([{"role": "user", "content": query}],
add_generation_prompt=True,
tokenize=True,
return_tensors="pt",
return_dict=True
)
inputs = inputs.to(device)
model = AutoModelForCausalLM.from_pretrained(
"THUDM/glm-4-9b-chat",
torch_dtype=torch.bfloat16,
low_cpu_mem_usage=True,
trust_remote_code=True
).to(device).eval()
gen_kwargs = {"max_length": 2500, "do_sample": True, "top_k": 1}
with torch.no_grad():
outputs = model.generate(**inputs, **gen_kwargs)
outputs = outputs[:, inputs['input_ids'].shape[1]:]
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
快速调用 GLM-4V-9B 多模态模型
使用 transformers 后端进行推理:
import torch
from PIL import Image
from transformers import AutoModelForCausalLM, AutoTokenizer
device = "cuda"
tokenizer = AutoTokenizer.from_pretrained("THUDM/glm-4v-9b", trust_remote_code=True)
query = '描述这张图片'
image = Image.open("your image").convert('RGB')
inputs = tokenizer.apply_chat_template([{"role": "user", "image": image, "content": query}],
add_generation_prompt=True, tokenize=True, return_tensors="pt",
return_dict=True) # chat mode
inputs = inputs.to(device)
model = AutoModelForCausalLM.from_pretrained(
"THUDM/glm-4v-9b",
torch_dtype=torch.bfloat16,
low_cpu_mem_usage=True,
trust_remote_code=True
).to(device).eval()
gen_kwargs = {"max_length": 2500, "do_sample": True, "top_k": 1}
with torch.no_grad():
outputs = model.generate(**inputs, **gen_kwargs)
outputs = outputs[:, inputs['input_ids'].shape[1]:]
print(tokenizer.decode(outputs[0]))注意: GLM-4V-9B 暂不支持使用 vLLM 方式调用。
进一步了解
如果想进一步了解GLM-4-9B系列模型的使用和开发,可以访问GLM-4-9B GitHub仓库,获取更多的文档和代码示例。
有需要的话,我们可以搞一个Windows系统下本地运行的一键包!

关于作者
tony
I am nobody !