DeepSeekR1 苹果macbook M1本地可视化运行!
过年了,就带了一台 macbook air 8g,DeepSeekR1的消息还是铺天盖地的来,我就想着在这台电脑上也装一个吧。
经过简单的配置,最终也运行起来了,速度还可以。
我这是首款M系列笔记本,也是现在最低配的 M 系列笔记本。
这也就意味着所有M系列的苹果电脑都可以轻松运行DeepSeekR1。

使用方法,就用上篇中讲到的 Ollama + ChatWise的方法!不需要任何编程知识,只要两行命令,其他全部点点就可以了。只要苹果电脑有了,其他基本有手就行。
下面就完整的记录下配置过程。
1.安装 Ollama
Ollama 是一个可以快速高效多平台运行大语言模型的工具。
有如下特点:
本地运行
无需联网,直接在个人电脑上部署LLM,可以保障数据隐私。
多模型支持
内置模型库包含DeepSeekR1,Qwen,Llama、Mistral、Gemma 等热门模型。
跨平台兼容
支持Windows,macOS(M/Inter)、Linux等操作系统。
使用简单
命令行工具一键启动(如 ollama run llama2),集成REST API便于与其他应用交互。
轻量高效
对硬件要求较低,部分模型可在消费级GPU或CPU上流畅运行。
Ollama在苹果电脑 macOS 系统上的安装也非常简单。
只要打开官网 Ollama.com。
点击 Download 进入下载页。

在下载页面选择 macOS,然后直接点击 Download for macOS 就可以开始下载了。
下载地址来自于 github,所以要确保你能打开 github。
下载完成之后是一个.zip的压缩包。
苹果电脑上可以直接双击这个文件,自动解压。然后会看到 Ollama 的羊驼图标。
双击打开
打开之后再点击“打开” 。
然后点击 Move to Applications 把软件自动移动到应用目录。

安装完成之后会自动启动,右上角会出现羊驼图标。以后也可以在启动台找到这个软件。
安装完成之后,可以打开终端,输入 ollama 测试一下。
输入后跳出一堆英文的帮助信息,就可以证明软件已安装并启动。
终端,可以通过按 Command+空格,输入终端,然后按 return 打开。
2.下载 DeepSeekR1
Ollama安装完成之后,就可以通过 Ollama 来下载DeepSeekR1了。
打开终端,输入命令:
ollama run deepseek-r1#ollama pull deepseek-r1#ollama run qwen2.5#ollama run minicpm-v只要输入第一行命令按回车(return),就会自动下载并运行 deepseekr1 模型了。
默认下载 70 亿参数的 7B 模型。
当然也可以用第二行的命令,只是单纯下载而不运行。
第三行是下载 qwen2.5,一个综合实力很强的国产大语言模型。可以下载,也可以不下载。下载之后,后面的环节会有一些作用。
第四行命令,可以下载一个多模态模型,比如可以识别图片文件等信息。这个不是必须的,根据自己的需要下载。
3.安装 ChatWise
ChatWise是一个和大语言模型对话的可视化软件。
简洁好用,主要有如下特点:
支持广泛
- 兼容几乎所有主流大语言模型(LLMs),包括 GPT-4、Claude、Gemini、DeepSeek 等闭源模型,以及通过 Ollama 本地运行的开源模型(如DeepSeekR1、Qwen2.5、 Llama 3等)
本地化和隐私保护
- 所有聊天记录和数据默认存储在本地设备,使用开源模型的场景下,可以完全离线,本地运行。
多模态交互与实用功能
- 支持文本、音频、PDF、图像等多种文件格式的输入与解析,部分模型(如 GPT-4o、Claude 3.5)可直接处理多模态内容。
- 内置免费网页搜索(基于 Tavily),可快速获取实时信息,并支持数学公式渲染(LaTeX)、HTML/SVG 显示等专业功能。
跨平台与轻量化设计
- 提供 macOS、Windows客户端,界面简洁美观。
- 支持聊天记录管理(删除、复制)、自动命名对话,分栏式布局提升操作效率。
安装 chatwise 也非常简单。
直接打开chatwise.app网站,点击 Download。

根据自己的系统进行选择。苹果系统选择 macOS,如果是 M 系列,选择 AppleSillicon,如果是 老款Inter系列,就选择 Inter。
下载完成之后点击 dmg文件,然后点击 chatwise,将 ChatWise 拖动到 Applications 里面。
然后就可以双击启动软件了。
启动之后设置一下 ollama 的 Base URL。
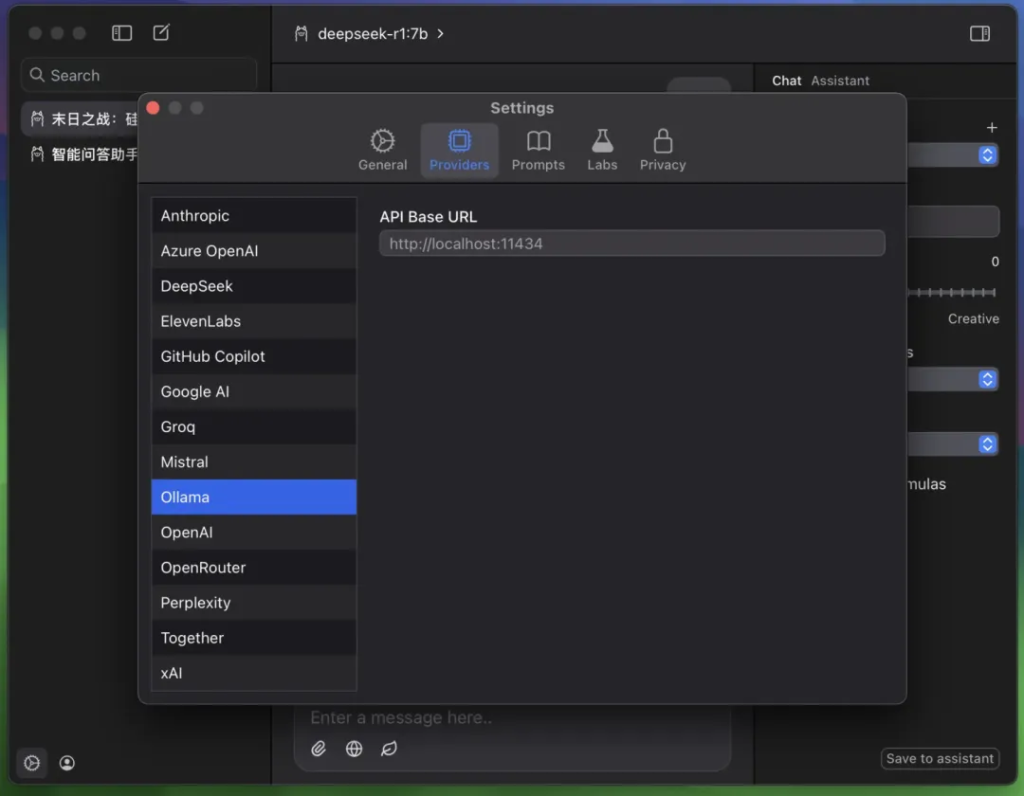
点击软件左下角的设置,然后点击 Providers,点击 Ollama。
输入http://localhost:11434 (默认都是这个地址)。
这样就设置好了。
其实 Ollama 不需要设置。只要本地的启动 Ollama 并下载模型之后,ChatWise 会自动刷新他的模型列表。
这个设置界面可以配置很多模型。
比如 :
Anthropic 的 Cluade,编程能力很强。
OpenAI 的 ChatGPT,比较有代表性的大语言模型。
Github Copilot,专门用来编程。
DeepSeeK 在线版,会比开源版强一些。
XAI 马斯克旗下的AI模型。
GoogleAI,谷歌的模型,现在也很强。
只要获取他们的 API key 在这里配置一下,就可以快速使用。
4.使用 DeepSeekR1
万事俱备之后,只要在 ChatWise 中上区域下拉列表中选中 DeepSeek 就可以了。
选中模型之后,立马就可以进行对话,测试 DeepSeekR1 的能力了。
比如我让他列出他的主要功能:

他根据上下文先进行了一番思考<think>,然后最后给了具体的回答:1,2,3,4,5,6…。DeepSeekR1 这种先显示思考内容,然后输出结果的模式,非常有特色。
ChatWise也能完整的显示思考的内容以及思考时间。
70 亿参数的 7B模型,在2020款苹果轻薄本 Macbook air M1 上的速度基本也在可以接受的范围内。
具体的速度如下:
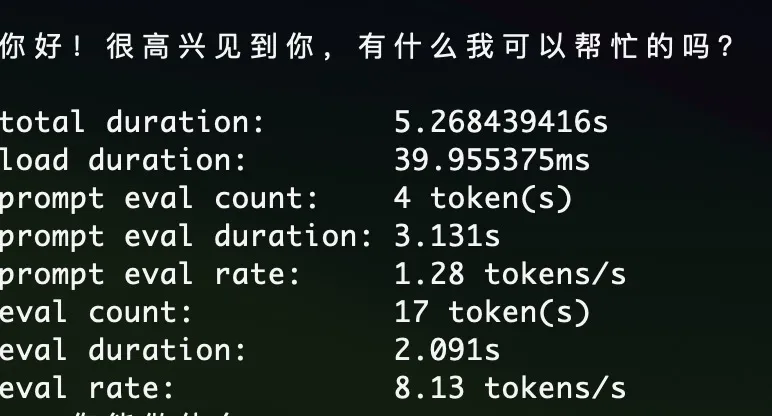
每秒 8 token ,流式输出的时候感觉还可以,因为内容一直在匀速的输出,没有卡顿的感觉。
15 亿参数的 1.5B 模型速度如下:

每秒 36token,这个速度就很快了,刷刷的跳出来。
但是,强烈推荐 7B 以上模型,1.5B 虽然也可以用,但是思维能力会降低很多。7B 是能用,13B 比较好用,在大一点效果会更好。
macOS 上运行 DeepSeek R1 记录就写到这里了。
后续有空会尝试下直接在iphone手机上运行,还是一种方案是以家里的电脑为服务器,内网穿透,然后在 iPhone手机App上使用自己的大模型服务。

28个大模型,免费,在线体验!包括GPT4,Gemini Pro,Claude2

最近DeepSeek 确实挺忙,网页繁忙,API资源紧张。

AI大乱斗:识别图中人物,ChatGPT碾压谷歌和国产AI产品
关于作者
tony
I am nobody !